
본 게시글은 '아파치 카프카 애플리케이션 프로그래밍 with 자바'를 읽고 개인적으로 정리한 내용입니다.
이번 포스팅에서는 카프카의 역사와 각 컴포넌트들의 특징, 관련 생태게(카프카 스트림즈, 카프카 커넥트, 카프카 미러메이커2)에 대해 알아보자.
카프카 브로커 / 클러스터 / 주키퍼
- 카프카 브로커(Kafka Broker): 카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체
- 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션
- 데이터를 안전하게 보관하고 처리하기 위해서 보통 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영
카프카 브로커의 역할

- 데이터 저장, 전송
- 프로듀서로부터 데이터를 전달받고, 이를 요청한 토픽의 파티션에 데이터를 저장
- 컨슈머가 데이터를 요청하면, 파티션에 저장된 데이터를 전달
- 전달된 데이터는 파일 시스템에 저장되는데, 페이지 캐시(page cache)를 사용하여 디스크 입출력 속도를 높여 입출력 성능을 향상시킴
- 페이지 캐시: OS에서 파일 입출력의 성능 향상을 위해 만들어 놓은 메모리 영역으로, 한번 읽은 파일의 내용은 메모리의 페이지 캐시 영역에 저장시키고, 추후 동일한 파일의 접근이 일어나면 디스크에서 읽지 않고 메모리에서 직접 읽는 방식이다.
- 카프카를 실행할 때 config/server.properties의 log.dir 옵션에 정의한 디렉토리에 데이터를 저장
- 토픽이름(hello.kafka)과 파티션 번호(0)의 조합으로 하위 디렉토리를 생성하여 데이터를 저장
$ ls /tmp/kafka-logs/hello.kafka-0: hello-kafka 토픽의 0번 파티션 내부에 저장된 데이터를 확인할 수 있음log에는 메시지와 메타데이터를 저장index는 메시지의 오프셋을 인덱싱한 정보를 담은 파일timeindex파일에는 메시지에 포함된 timestamp 값을 기준으로 인덱싱한 정보가 담김
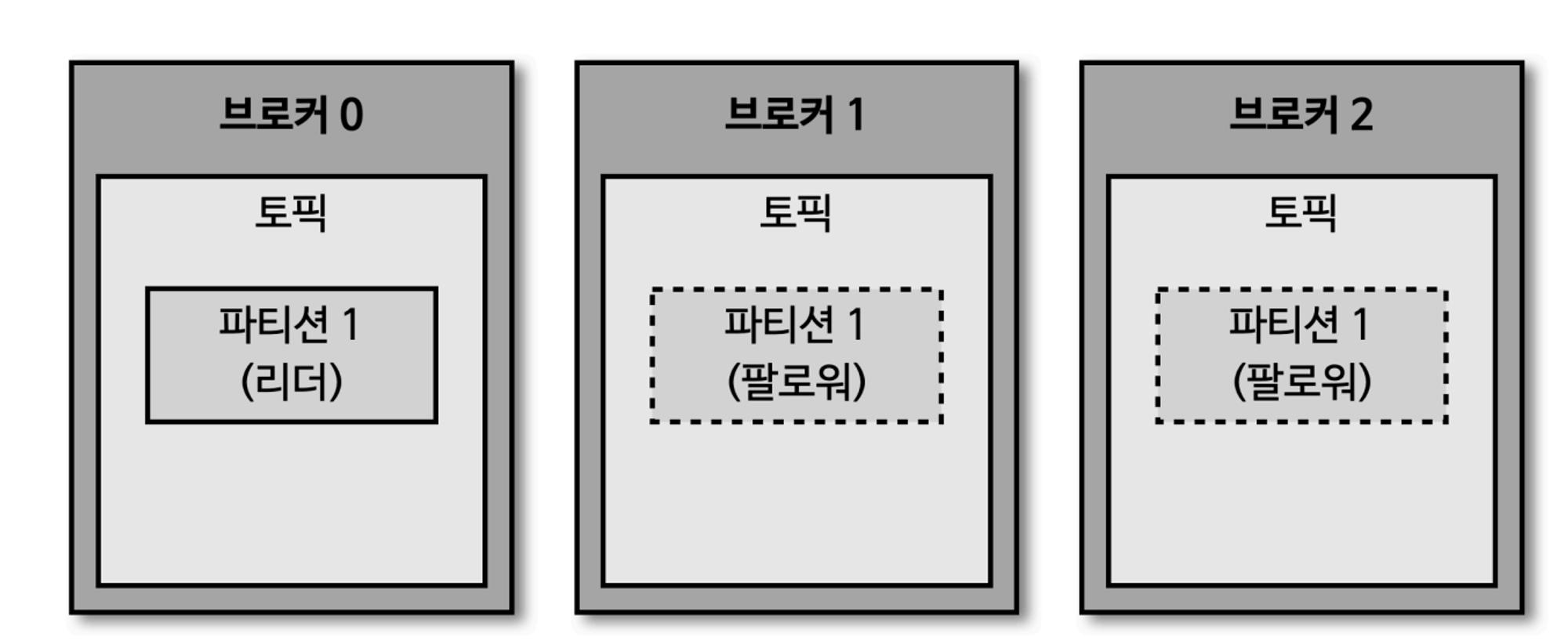
- 데이터 복제, 싱크
- 데이터 복제(replication)는 카프카를 장애 허용시스템(fault-tolerant system)으로 동작하도록 하는 원동력
- 복제는 클러스터로 묶인 브로커 중 일부에 장애가 발생하더라도 데이터를 유실하지 않고 안전하게 사용하기 위함
- 데이터 복제는 파티션 단위로 이루어짐
- 토픽 생성 시 파티션의 복제 개수(
--replication-factor옵션)도 같이 설정되는데, 직접 옵션을 선택하지 않으면 브로커에 설정된 옵션 값을 따라감 - 복제 개수의 최솟값은 1(복제 없음)이고, 최댓값은 브로커 개수만큼 설정하여 사용 가능
- 리더 파티션: 프로듀서 또는 컨슈머와 직접 통신하는 파티션
- 팔로워 파티션: 나머지 복제 데이터를 가지고 있는 파티션
- 토픽 생성 시 파티션의 복제 개수(
- 팔로워 파티션들은 리더 파티션의 오프셋을 확인하여 현재 자신이 가지고 있는 오프셋과 차이가 나는 경우, 리더 파티션으로부터 데이터를 가져와서 자신의 파티션에 저장 -> 복제(replication)
- 장점: 데이터를 안전하게 사용 가능 (단, 복제 개수(replication factor)는 2 이상)
- 단점: 복제 개수만큼의 저장 용량이 증가
- 리더 파티션이 있는 브로커가 다운되면, 다른 브로커에 있는 팔로워 파티션 중 하나가 리더 파티션으로 승격
- 운영 시에는 데이터 종류마다 다른 복제 개수를 설정하고 상황에 따라서는 토픽마다 복제 개수를 다르게 설정하여 운영하기도 함
- 일부 유실되어도 무관하고, 처리 속도가 중요하다면
--replication-factor를 1 또는 2 (복제 X 또는 복제 1개)로 설정
- 일부 유실되어도 무관하고, 처리 속도가 중요하다면
- 컨트롤러(Controller)
- 컨트롤러: 다른 브로커들의 상태를 체크하고 브로커가 클러스터에서 빠지는 경우 해당 브로커에 존재하는 리더 파티션을 재분배하는 역할
- 클러스터의 다수 브로커 중 한 대가 컨트롤러 역할 수행
- 컨트롤러 역할을 하는 브로커에 장애가 생길 경우, 다른 브로커가 컨트롤러 역할
- 데이터 삭제
- 카프카는 다른 메시징 플랫폼과 다르게 컨슈머가 데이터를 가져가더라도 토픽의 데이터는 삭제되지 않으며, 컨슈머나 프로듀서가 데이터 삭제를 요청할수도 없음
- 오직 브로커만 데이터를 삭제할 수 있음
- 데이터 삭제는 '로그 세그먼트(log segment)'라는 파일 단위로 이루어짐
- 세그먼트는 데이터가 쌓이는 동안 파일 시스템으로 계속 열려있음
- 세그먼트 파일 닫히는 기준 설정
log.segment.bytes또는log.segment.ms옵션 값 설정- 기본값은
log.segment.bytes=1073741824로 1GB
- 닫힌 세그먼트 파일 삭제 기준 설정
log.retention.bytes또는log.retention.ms옵션 값 설정
- 닫힌 세그먼트 파일 체크 간격 설정 for 삭제
log.retention.check.interval옵션 값 설정
- 데이터를 삭제하지 않고 메시지 키를 기준으로 오래된 데이터를 압축하는 정책을 가져갈 수도 있는데 이는 이후 포스팅에서 다룸
- 카프카는 다른 메시징 플랫폼과 다르게 컨슈머가 데이터를 가져가더라도 토픽의 데이터는 삭제되지 않으며, 컨슈머나 프로듀서가 데이터 삭제를 요청할수도 없음
- 컨슈머 오프셋 저장
- 컨슈머 그룹은 토픽이 특정 파티션으로부터 데이터를 가져가서 처리하고, 이 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 '커밋'
- 커밋한 오프셋은
__consumer_offsets토픽에 저장
- 코디네이터(coordinator)
- 코디네이터: 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배하는 역할 수행
- 클러스터의 다수 브로커 중 한 대는 코디네이터의 역할 수행
- 리밸런스(rebalance): 파티션을 컨슈머로 재할당하는 과정
- 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 재할당(리밸런싱)하여 끊임없이 데이터가 처리되도록 해야 함.
주키퍼(zookeeper)의 역할
- 주키퍼는 카프카의 메타데이터를 관리하는 데에 사용
bin/zookeeper-shell.sh localhost:2181- localhost:2181로 접속하여 해당 인스턴스에서 실행되는 주키퍼에 접속
- 주키퍼 쉘을 통해 znode를 조회하고 수정 가능
znode: 주키퍼에서 사용하는 데이터 저장 단위로, 파일 시스템처럼 znode 간에 계층 구조가 있다- 이후
ls /명령어를 통해 root znode의 하위 znode를 확인- 카프카 실행 시 주키퍼의 하위 경로로 지정하지 않았으므로 카프카는 root znode를 기준으로 데이터를 저장
get /brokers/ids/0: 카프카 브로커에 대한 정보 확인get /controller: 어느 브로커가 컨트롤러인지에 대한 정보 확인ls /brokers/topics: 카프카에 저장도니 토픽들 확인
- 카프카 클러스터로 묶인 브로커들은 동일한 경로의 주키퍼 경로로 선언해야 같은 카프카 브로커 묶음이 됨
- 다수의 카프카 클러스터를 운영하려면, 주키퍼의 서로 다른 znode에 카프카 클러스터들을 설정하면 된다. 때문에 root znode(최상위 znode)가 아닌, 한 단계 아래의 znode를 카프카 브로커 옵션으로 지정하도록 한다. 각기 다른 하위 znode로 설정된 서로 다른 카프카 클러스터는 각 클러스터의 데이터에 영향을 미치지 않고 정상 동작한다.
토픽과 파티션
- 토픽(topic): 카프카에서 데이터를 구분하기 위해 사용하는 단위
- 토픽은 1개 이상의 '파티션' 소유
- 파티션에는 프로듀서가 보낸 데이터들이 저장되는데 이 데이터를 '레코드(record)'라고 부름
- 파티션은 카프카의 병렬처리의 핵심으로써 그룹으로 묶인 컨슈머들이 레코드를 병렬로 처리할 수 있도록 매칭됨
- 컨슈머의 처리량이 한정된 상황에서 많은 레코드를 병렬로 처리하는 가장 좋은 방법 = 컨슈머 수를 늘려 스케일 아웃(scale-out) + 동시에 파티션 개수도 늘리기
- 파티션은 큐(queue) 자료구조와 비슷한 구조
- 파티션의 레코드는 컨슈머가 가져가는 것과 별개로 관리됨
- 때문에 레코드는 다양한 목적을 가진 여러 컨슈머 그룹들이 토픽의 데이터를 여러 번 가져갈 수 있음
토픽 이름 제약 조건
- 빈 문자열 불가능
- 마침표 하나(.) 또는 마침표 둘(..)로 설정 불가
- 길이는 249자 미만
- 대소문자와 숫자 0~9, 그리고 마침표(.), 언더바(_), 하이픈(-) 조합으로 생성 가능
__consumer_offsets와__transaction_state는 예약어로 사용 불가- 토픽 이름에 마침표(.)와 언더바(_)가 동시에 들어갈 수 없음. 생성은 가능하지만, 사용 시 이슈가 발생할 수 있기 때문에 마침표(.)와 언더바(_)가 들어간 토픽 이름을 사용하면 경고 메시지 발생
- 이미 생성된 토픽 이름의 마침표(.)를 언더바(_)로 바꾸거나, 언더바(_)를 마침표(.)로 바꾼 경우 신규 토픽 이름과 동일하다면 생성할 수 없음
의미 있는 토픽 이름 작명 방법
- 어떤 개발 환경에서 사용되는 것인지 판단 가능하고, 어떤 애플리케이션에서 어떤 데이터 타입으로 사용되는지 유추할 수 있어야 함
- 케밥케이스(kebab-case) 또는 스네이크 표기법(snake_case)과 같이 소문자를 쓰되 구분자로 특수문자를 조합하여 사용하길 권장
- 템플릿과 예시
- <환경>.<팀-명>.<애플리케이션명>.<메시지타입>
- ex) prd.marketing-team.sms-platform.json
- <프로젝트명>.<서비스명>.<환경>.<이벤트명>
- ex) commerce.payment.prd.notification
- <환경>.<서비스명>.<JIRA-번호>.<메시지타입>
- ex) dev.email-sender.jira-1234.email-vo-custom
- <카프카 클러스터 명>.<환경>.<서비스명>.<메시지타입>
- ex) aws-kafka.live.marketing-platform.json
- <환경>.<팀-명>.<애플리케이션명>.<메시지타입>
- 카프카는 토픽 이름 변경을 지원하지 않으므로, 이름을 변경하기 위해서는 삭제 후 다시 생성하는 것 외에는 방법이 없다.
레코드
- 레코드의 구성 요소: 타임스탬프, 메시지 키, 메시지 값, 오프셋, 헤더
- 레코드가 브로커로 전송되면 오프셋과 타임스탬프가 지정되어 저장되며, 한번 적재된 레코드는 수정 불가하고, 로그 리텐션 기간 또는 용량에 따라서만 삭제됨
- 타임스탬프: 프로듀서에서 해당 레코드가 생성된(CreateTime) 시점의 유닉스 타임이 설정
- 프로듀서가 레코드를 생성할 때 임의의 타임스탬프 값을 설정할 수도 있음
- 토픽 설정에 따라 브로커에 적재도니 시간(LogAppendTime)으로 설정될 수도 있음
- 메시지 키: 메시지 값을 순서대로 처리하거나 메시지 값의 종류를 나타내기 위해 사용
- 메시지 키의 해시값을 토대로 파티션을 지정하므로, 동일한 메시지 키라면 동일 파티션에 적재
- 파티션 개수가 변경되면 메시지 키와 파티션 매칭이 달라질 수 있음
- 메시지 키를 선언하지 않으면 null로 설정되며, 프로듀서 기본 설정 파티셔너에 따라 파티션에 분배되어 적재됨
- 메시지 값: 실질적으로 처리할 데이터
- '프로듀서에서 전송할 때'와 '컨슈머에서 이용할 때' 서로 동일한 형태로 직렬화/역직렬화를 수행해야 함
- 오프셋: 0 이상의 숫자로 이루어지며, 카프카 컨슈머가 데이터를 가져갈 때 사용
- 직접 지정할 수 없고, 브로커에 저장될 때 이전에 전송된 레코드의 오프셋 + 1 값으로 생성됨
- 오프셋을 통해 컨슈머 그룹으로 이루어진 카프카 컨슈머들이 파티션의 데이터를 어디까지 가져갔는지 명확히 지정 가능 (커밋)
- 헤더: 레코드의 추가적인 정보를 담는 메타데이터 저장소 용도
- 키/값 형태로 데이터를 추가하여 레코드의 속성(스키마 버전 등)을 저장하여 컨슈머에서 참조 가능
카프카 클라이언트(Kafka Client) - 프로듀서 API
카프카 클러스터에 명령을 내리거나 데이터를 송수신하기 위해 카프카 프로듀서, 컨슈머, 어드민 클라이언트를 제공하는 카프카 클라이언트를 사용하여 애플리케이션을 개발한다. 카프카 클라이언트는 라이브러리이기 때문에 자체 라이프사이클을 가진 프레임워크나 애플리케이션 위에서 구현하고 실행해야 한다. 여기서는 카프카 클라이언트 라이브러리를 이용한 프로듀서, 컨슈머, 어드민 클라이언트를 각각 자바 애플리케이션으로 구현해보도록 하겠다.
먼저, 프로듀서를 구현하는 가장 기초적인 방법은 카프카 클라이언트를 라이브러리로 추가하여 자바 기본 애플리케이션을 만드는 것이다. 프로듀서는 데이터를 직렬화하여 카프카 브로커로 보내기 때문에 자바에서 선언 가능한 모든 형태를 브로커로 전송할 수 있다.
기본적인 프로듀서 애플리케이션
build.gradle은 다음과 같다.
plugins {
id 'java'
}
group = 'com.maruhxn'
version = '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.apache.kafka:kafka-clients:2.5.0'
implementation 'org.slf4j:slf4j-simple:2.0.13'
testImplementation platform('org.junit:junit-bom:5.10.0')
testImplementation 'org.junit.jupiter:junit-jupiter'
}
test {
useJUnitPlatform()
}
가장 기본적인 형태의 프로듀서를 살펴보자. 각 코드에 대한 설명은 주석을 통해 남겨두었다.
SimpleProducer
public class SimpleProducer {
private final static Logger logger = LoggerFactory.getLogger(SimpleProducer.class);
// 전송하고자 하는 토픽의 이름(필수)
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
Properties configs = new Properties();
// 전송하고자 하는 카프카 클러스터 서버의 host와 IP 지정
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 메시지 키, 메시지 값을 직렬화하기 위한 직렬화 클래스 선언
// 여기서는 String 객체 전송을 위해 String을 직렬화하는 클래스인 StringSerializer 사용
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// Properties를 KafkaProducer의 생성 파라미터로 추가하여 인스턴스 생성
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
// 카프카 브로커로 데이터를 보내기 위해 ProducerRecord 생성
// 각 제네릭은 메시지 키와 메시지 값의 타입을 뜻한다. 이는 직렬화 클래스와 동일하게 설정해야 한다.
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "testMessage"); // 메시지 키 설정하지 않았으므로 null
ProducerRecord<String, String> record2 = new ProducerRecord<>(TOPIC_NAME, "Pangyo", "23");
ProducerRecord<String, String> record3 = new ProducerRecord<>(TOPIC_NAME, 0, "Gangnam", "24"); // 0번 파티션으로 전송
// ProducerRecord를 전송. 이는 즉각적인 전송이 아니라, 파라미터로 들어간 record를 프로듀서 내부에 가지고 있다가 배치 형태로 묶어서 브로커에 전송한다.
producer.send(record);
producer.send(record2);
producer.send(record3);
logger.info("{}", record);
// flush()를 통해 프로듀서 내부 버퍼에 가지고 있던 레코드 배치를 브로커로 전송
producer.flush();
// 애플리케이션 종료 전 close() 메서드를 호출하여 producer 인스턴스의 리소스들을 안전하게 종료
producer.close();
}
}
위를 실행하면 토픽에 3개의 메시지를 전송하게 되는데, 이를 위해서는 토픽을 먼저 생성해두어야 한다. 다음의 커맨드를 통해 생성하자
$ bin/kafka-topcis.hs --bootstrap-server localhost:9092 --create --topic test --partitions 3
Created topic test.
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --property print.key=true --property key.separator="-" --from-beginning
null-testMessage
Pangyo-23
Gangman-24프로듀서 중요 개념
프로듀서는 카프카 브로커로 데이터를 전송할 때 내부적으로 파티셔너, 배치 생성 단계를 거친다.

- KafkaProducer 인스턴스가 send() 메서드를 호출하면 ProducerRecord는 파티셔너에서 토픽의 어느 파티션으로 전송될 것인지 정해짐
- 파티셔너를 따로 설정하지 않으면 기본값인
DefaultPartitioner로 설정 UniformStickyPartitioner와RoundRobingPartitioner2개 파티션이 제공되는데,UniformStickyPartitioner가 기본 설정된다.- 둘 다 메시지 키가 있을 때는 메시지 키의 해시값과 파티션을 매칭하여 데이터를 전송한다는 점이 동일
RoundRobingPartitioner은 레코드가 들어오는 대로 파티션을 순회하면서 전송하기 때문에 배치로 묶이는 빈도가 적다는 단점이 있음- 반면,
UniformStickyPartitioner는 어큐뮬레이터에서 데이터가 배치로 모두 묶일 때까지 기다렸다가 배치로 묶은 데이터는 모두 동일한 파티션에 전송하기 때문에 상대적으로 높은 처리량과 낮은 리소스 사용률을 보임
- 파티셔너를 따로 설정하지 않으면 기본값인
- 카프카 클라이언트 라이브러리에서는 사용자 지정 파티셔너를 생성하기 위한
Partitioner인터페이스를 제공 - 파티셔너에 의해 구분된 레코드는 데이터를 전송하기 전에 어큐뮬레이터(accumulator)에 데이터를 버퍼로 쌓아놓고 발송
- 버퍼로 쌓인 데이터를 배치로 묶어 전송함으로써 카프카 프로듀서 처리량을 향상시킨다
- 센더(sender) 스레드는 어큐뮬레이터에 쌓인 배치 데이터를 가져가 카프카 브로커로 전송
- 카프카 프로듀서는 압축 옵션을 통해 브로커로 전송 시 압축 방식을 지정 가능
- 압축 옵션 지정하지 않으면 압축 X
- 가능한 압축 옵션: gzip, snappy, lz4, zstd
- 압축 시 네트워크 처리량에 이득을 볼 수 있지만, 압축을 할 때와 컨슈머에서 이를 압축 해제 하는데에 CPU 또는 메모리 리소를 사용하게 됨
프로듀서 주요 옵션
- 필수 옵션
bootstrap.servers: 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 hostname:port 를 1개 이상 작성- 2개 이상 브로커 정보를 입력하여 일부 브로커에 이슈가 발생하더라도 접속하는데에 이슈가 없도록 설정 가능
key.serializer: 레코드의 메시지 키를 직렬화 하는 클래스 지정value.serializer: 레코드의 메시지 값을 직렬화 하는 클래스 지정
- 선택 옵션
acks: 프로듀서가 전송한 데이터가브로커들에 정상적으로 저장되었는지 전송 성공 여부를 확인하는 데에 사용하는 옵션- 0은 전송 즉시 성공으로 빠른 전송을 의미하지만, 일부 메시지 손실 가능성 있음
- 1은 리더가 메시지를 받았는지 확인하지만, 팔로워 파티션을 전부 확인하지 않음
- -1또는 all은 min.insync.replicas 개수에 해당하는 리더 파티션과 팔로워 파티션에 데이터가 저장되면 성공하는 것으로 판단. 다소 느릴 수 있으나 하나의 팔로우가 있는 한 메시지 손실은 없음
buffer.memory: 브로커로 전송할 데이터를 배치로 모으기 위해 설정할 버퍼 메모리양 설정- 기본값은 33554432(32MB)
retries: 프로듀서가 브로커로부터 에러를 받고 난 뒤 재전송을 시도하는 횟수 지정- 기본값은 214783647
batch.size: 배치로 전송할 레코드 최대 용량을 지정- 너무 작게 설정하면 프로듀서가 브로커로 더 자주 보내기 때문에 네트워크 부담이 있고 너무 크게 설정하면 메모리를 더 많이 사용
- 기본값은 16384
linger.ms: 배치를 전송하기 전까지 기다리는 최소 시간- 기본값은 0
partitioner.class: 레코드를 파티션에 전송할때 적용하는 파티셔너 클래스를 지정- 기본값은 org.apache.kafka.clients.producer.internals.DefaultPartitioner
enable.idempotence: 멱등성 프로듀서로 동작할지 여부를 설정- 기본값은 false
transactional.id: 프로듀서가 레코드를 전송할때 레코드를 트랜잭션 단위로 묶을지 여부를 설정- 프로듀서의 고유한 트랜잭션 아이디를 설정 가능
- 이 값을 설정하면 트랜잭션 프로듀서로 동작
- 기본값은 null
커스텀 파티셔너를 가지는 프로듀서
CustomPartitioner
public class CustomPartitioner implements Partitioner {
// 레코드를 기반으로 파티션을 정하는 로직 포함. 반환값은 주어진 레코드가 들어갈 파티션 번호
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 레코드에 메시지 키를 지정하지 않은 경우에는 비정상적인 데이터로 간주하고 InvalidRecordException을 발생
if(keyBytes == null || keyBytes.length == 0) {
throw new InvalidRecordException("Need message key");
}
// 메시지 키가 Pangyo일 경우 파티션 0번으로 지정되도록 0을 리턴한다.
if(key.equals("testest")) return 0;
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// "testest"가 아닌 메시지 키를 가진 레코드는 해시값을 지정하여 특정 파티션에 매칭되도록 설정
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
CustomPartitionerProducer
public class CustomPartitionerProducer {
private final static Logger logger = LoggerFactory.getLogger(CustomPartitionerProducer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// PARTITIONER_CLASS_CONFIG 옵션을 통해 커스텀 파티셔너 지정
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
ProducerRecord<String, String> pangyoRecord = new ProducerRecord<>(TOPIC_NAME, "Pangyo", "23");
ProducerRecord<String, String> normalRecord = new ProducerRecord<>(TOPIC_NAME, "Jeju", "24");
producer.send(pangyoRecord);
producer.send(normalRecord);
producer.flush();
producer.close();
}
}
브로커 정상 전송 여부를 확인하는 프로듀서
KafkaProduer의 send() 메서드는 Future 객체를 반환한다.이는 RecordMetadata의 비동기 결과를 표현하는 것으로, ProduerRecord가 카프카 브로커에 정상적으로 적재되었는지에 대한 데이터가 포함되어 있다. get() 메서드를 통해 데이터 결과를 '동기적'으로 가져올 수 있으나, 동기적으로 프로듀서의 전송 결과를 확인하는 것은 전송에 대한 응답 값을 받기 전까지 대기하므로 전송 속도를 늦출 우려가 있다.
SyncCallbackProduer
public class SyncCallbackProducer {
private final static Logger logger = LoggerFactory.getLogger(AsyncCallbackProducer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "TEST", "11");
// send() 후 get() 메서드를 통해 데이터의 결과를 동기적으로 가져올 수 있음
RecordMetadata metadata producer.send(record).get();
logger.info(metadata.toString());
producer.flush();
producer.close();
}
}
동기적인 응답값 확인은 빠른 전송의 허들이 될 수 있으므로, 프로듀서는 비동기로 결과를 확인할 수 있도록 Callback 인터페이스를 제공한다. 사용자는 사용자 정의 Callback 클래스를 생성하여 데이터 전송 결과에 대응하는 로직을 만들 수 있다.
ProducerCallback
public class ProducerCallback implements Callback {
private final static Logger logger = LoggerFactory.getLogger(ProducerCallback.class);
// 레코드의 비동기 결과를 받기 위해 사용되는 메서드
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
logger.error(e.getMessage(), e);
} else {
logger.info(recordMetadata.toString()); // 해당 레코드가 적재된 토픽 이름과 파티션 번호, 오프셋을 알 수 있다
}
}
}
레코드 전송 후 비동기로 결과를 받기 위해서는 send() 호출 시 ProducerRecord 객체와 함께 사용자 정의 Callback 클래스를 넣으면 된다. 비동기로 결과를 받을 경우 동기로 결과를 받는 경우보다 더 빠른 속도로 데이터를 추가 처리할 수 있지만, 전송하는 데이터의 순서가 역전될 수 있기에 순서가 중요한 경우에는 사용해서는 안된다.
AsyncCallbackProducer
public class AsyncCallbackProducer {
private final static Logger logger = LoggerFactory.getLogger(AsyncCallbackProducer.class);
// 전송하고자 하는 토픽의 이름(필수)
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "TEST", "11");
// send()시 파라미터로 ProducerCallback 지정
producer.send(record, new ProducerCallback());
producer.flush();
producer.close();
}
}카프카 클라이언트(Kafka Client) - 컨슈머 API
기본적인 컨슈머 애플리케이션
public class SimpleConsumer {
private final static Logger logger = LoggerFactory.getLogger(SimpleConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
// 컨슈머 그룹 이름을 선언한다.
private final static String GROUP_ID = "test-group";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 역직렬화 클래스를 등록한다. 반드시 프로듀서에서 직렬화 한 타입으로 역직렬화 해야 한다.
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 컨슈머 그룹 이름을 전달한다.
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
// 컨슈머 인스턴스를 생성한다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
// 컨슈머에게 토픽을 할당한다. Collection 타입을 통해 1개 이상의 토픽을 전달할 수 있다.
// subscribe() 메서드를 통해 토픽을 구독하는 경우 컨슈머 그룹을 반드시 선언해야 한다. 컨슈머 그룹을 선언하지 않으면 어떤 그룹에도 속하지 않은 컨슈머로 동작한다.
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// 지속적인 반복 호출을 위해 무한 루프를 생성한다.
while (true) {
// 토픽으로부터 레코드들을 가져온다.
// Duration 타입을 인자로 받는데, 이는 브로커로부터 데이터를 가져올 때 컨슈머 버퍼에 데이터를 기다리기 위한 타임아웃 간격을 뜻한다.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
}
}
}
}
위 애플리케이션을 실행한 후, test에 데이터를 넣어 주기 위해 다음의 커맨드를 실행하자
$ bin/kafka-console-producer --bootstrap-server localhost:9092 --topic test
> testMessage
그러면 출력 화면에 polling을 통해 가져온 ConsumerRecord의 정보가 로그로 남았을 것이다.
컨슈머 중요 개념
- 컨슈머를 운영하는 방법 2가지
- 1개 이상의 컨슈머로 이루어진 컨슈머 그룹을 운영 (subscribe())
- 토픽의 특정 파티션만 구독하는 컨슈머를 운영 (assign())
그 중 컨슈머 그룹을 운영하는 방식에 대해 알아보자
- 컨슈머를 각 컨슈머 그룹으로부터 격리된 환경에서 안전하게 운영할 수 있도록 도와주는 방식
- 컨슈머 그룹으로 묶인 컨슈머들은 토픽의 1개 이상 파티션들에 할당되어 데이터를 가져갈 수 있음
- 1개의 파티션은 최대 1개의 컨슈머에 할당 가능 & 1개 컨슈머는 여러개의 파티션에 할당 가능
- 컨슈머 그룹의 컨슈머 개수를 가져가고자 하는 토픽의 파티션 개수보다 같거나 작아야함 (컨슈머 그룹의 컨슈머 개수 <= 토픽의 파티션 개수)
- 파티션 수보다 오버되는 컨슈머들은 파티션을 할당받지 못하고 유휴 상태로 남게되고, 이는 불필요한 스레드로 남게 된다.
컨슈머 그룹의 특징
- 컨슈머 그룹은 다른 컨슈머 그룹과 격리되는 특징을 가지고있다
- 카프카 프로듀서가 보낸 데이터를 각기 다른 역할을 하는 컨슈머 그룹끼리 영향을 받지 않게 처리할 수 있다
- 각기 다른 저장소에 저장되는 컨슈머를 다른 컨슈머 그룹으로 묶음으로써 각 저장소의 장애에 격리되어 운영 가능 -> 카프카는 파이프라인을 운영함에 있어 최종 적재되는 저장소의 장애에 유연하게 대응
- ex) 엘라스틱서치의 장애로 인해 더는 적재가 되지 못하더라도 하둡으로 데이터를 적재하는데에는 문제 없음. 엘라스틱서치의 장애가 해소되면 엘라스틱서치로 적재하는 컨슈머의 컨슈머 그룹은 마지막으로 적재 완료한 데이터 이후부터 다시 적재를 수행하여 최종적으로 모두 정상화 됨
- 적절히 컨슈머 그룹을 분리하여 운영하는 것이 매우 중요
- 분리하여 운영할 수 있음에도 불구하고 동일 컨슈머 그룹으로 묶어버린다면 장애가 전파될 수 있음
- 현재 운영하고 있는 토픽의 데이터가 어디에 적재되는지, 어떻게 처리되는지 파악하고 컨슈머 그룹으로 따로 나눌 수 있는 것은 최대한 나누는 것이 좋음
리밸런싱
컨슈머 그룹의 컨슈머에 장애가 발생할 경우 '리밸런싱(rebalancing)'을 수행한다.
- 리밸런싱: 장애가 발생한 컨슈머에 할당된 파티션의 소유권이 장애가 발생하지 않은 컨슈머에게로 넘어가는 것
- 리밸런싱 발생 상황
- 컨슈머가 추가되는 상황
- 컨슈머가 제외되는 상황
- 이슈로 인해 데이터 처리에 지연을 발생시키는 컨슈머를 컨슈머 그룹으로부터 제외하여 가용성을 높인다
- 리밸런싱은 컨슈머가 데이터를 처리하는 도중에 언제든지 발생할 수 있으므로 데이터 처리 중 발생한 리밸런싱에 대응하는 코드를 작성해야 함
이러한 리밸런싱은 유용하지만, 자주 발생해서는 안된다!
-> 리밸런싱이 발생할때 파티션의 소유권을 컨슈머로 재할당하는 과정에서 해당 컨슈머 그룹의 다른 컨슈머들이 토픽의 데이터를 읽을 수 없기 때문
-> 데이터 처리 지연 유발
- 그룹 조정자(group coodinator): 리밸런싱을 발동시키는 역할을 하는데, 컨슈머 그룹의 컨슈머가 추가되고 삭제될 때를 감지
- 카프카 브로커 중 한대가 그룹 조정자의 역할을 수행
오프셋 커밋

- 컨슈머는 카프카 브로커로부터 데이터를 어디까지 가져갔는지 커밋(commit)을 통해 기록
- 특정 토픽의 파티션을 어떤 컨슈머 그룹이 몇번째 가져갔는지 카프카 브로커 내부에서 사용되는 내부 토픽(
_consumer_offsets)에 기록 - 컨슈머 동작 이슈가 발생하여
_consume_offsets토픽에 어느 레코드까지 읽어갔는지 오프셋 커밋이 기록되지 못했다면 데이터 처리의 '중복'이 발생 가능 - 데이터 처리의 중복이 발생하지 않도록 컨슈머 애플리케이션이 오프셋 커밋을 정상적으로 처리했는지 검증해야 함
- 비명시적 오프셋 커밋
- 기본값.
enable.auto.commit = true - poll() 메서드가 수행될때 일정 간격마다 자동으로 오프셋을 커밋
auto.commit.interval.ms에 설정된 값 이상이 지났을때 그 시점까지 읽은 레코드의 오프셋을 커밋- 비명시 오프셋 커밋은 편리하지만, poll() 메서드 호출 이후에 리밸런싱 또는 컨슈머 강제 종료 발생시 컨슈머가 처리하는 데이터가 중복 또는 유실될 수 있는 가능성 존재
- 데이터 중복이나 유실을 허용하지 않는 서비스라면 자동 커밋을 사용 X
- 기본값.
- 명시적 오프셋 커밋
- poll() 메서드 호출 이후에 반환받은 데이터의 처리가 완료되고 commitSync() 메서드를 호출하면 됨
- commitSync() 메서드는 poll() 메서드를 통해 반환된 레코드의 가장 마지막 오프셋을 기준으로 커밋을 수행
- commitSync()은 브로커에 커밋 요청을 하고 커밋이 정상적으로 처리되었는지 응답하기까지 기다리는데 이는 컨슈머의 처리량에 영향을 줌 -> 동기적 방식
= 이를 해결하기 위해 commitAsync() 메서드를 사용하여 커밋 요청을 전송하고 응답이 오기 전까지 데이터 처리를 수행 -> 비동기적 방식- 하지만, 비동기 커밋은 커밋 요청이 실패했을 경우 현재 처리중인 데이터의 순서를 보장하지 않으며 데이터의 중복이 발생 가능
- poll() 메서드 호출 이후에 반환받은 데이터의 처리가 완료되고 commitSync() 메서드를 호출하면 됨
컨슈머 내부 구조

- 컨슈머는 poll 메서드를 통해 레코드를 반환하지만, poll() 메서드를 호출하는 시점에 클러스터에서 데이터를 가져오는 것은 아님
- 컨슈머 애플리케이션을 실행하게되면 내부에서
Fetcher인스턴스가 생성되어 poll() 메서드를 호출하기 전에 미리 레코드들을 내부 큐로 가지고 옴 - 이후 사용자가 명시적으로 poll() 메서드를 호출하면 컨슈머는 내부 큐에 있는 레코드들을 반환받아 처리를 수행
- 즉, Fetcher를 브로커에 요청하기 전 캐시로 사용한다고 볼 수 있다
다음은 poll() 메서드의 구현 코드이다

컨슈머 주요 옵션
- 필수 옵션
bootstrap.servers: 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 hostname:port 를 1개 이상 작성- 2개 이상 브로커 정보를 입력하여 일부 브로커에 이슈가 발생하더라도 접속하는 데에 이슈가 없도록 설정 가능
key.deserializer: 레코드의 메시지 키를 역직렬화하는 클래스를 지정value.deserializer: 레코드의 메시지 값을 역직렬화화는 클래스를 지정
- 선택 옵션
group.id: 컨슈머 그룹 아이디를 지정- subscribe() 메서드로 토픽을 구독하여 사용할때는 이 옵션은 필수
- 기본값은 null
auto.offset.reset: 컨슈머 그룹이 특정 파티션을 읽을때 저장된 컨슈머 오프셋이 없는 경우 어느 오프셋부터 읽을지 선택하는 옵션- 이미 컨슈머 오프셋이 있다면 이 옵션값은 무시
latest (default): 가장 높은(가장 최근에 넣은) 오프셋부터 읽기earliest: 가장 낮은(가장 오래 전에 넣은) 오프셋부터 읽기none: 컨슈머 그룹이 커밋한 기록이 있는지 찾아봐서 기록이 없으면 오류를 반환하고, 있다면 기존 커밋 기록 이후 오프셋부터 읽기enable.auto.commit: 자동 커밋으로 할지 수동 커밋으로 할지 선택
- 기본값은 true
auto.commit.interval.ms: 자동 커밋(enable.auto.commit = true)일 경우 오프셋 커밋 간격을 지정- 기본값은 5000(5초)
max.poll.records: poll() 메서드를 통해 반환되는 레코드 개수를 지정- 기본값은 500
session.timeout.ms: 컨슈머가 브로커와 연결이 끊기는 최대 시간- 이 시간 내에 하트비트를 전송하지 않으면 브로커는 컨슈머에 이슈가 발생했다고 가정하고 리밸런싱을 시작
- 보통 하트비트 시간 간격(
heatbeat.interval.ms)의 3배로 설정 - 기본값은 10000(10초)
heatbeat.interval.ms: 하트비트를 전송하는 시간 간격- 기본값은 3000(3초)
max.poll.interval.ms: poll() 메서드를 호출하는 간격의 최대 시간을 지정- poll() 메서드를 호출한 이후에 데이터를 처리하는데에 시간이 너무 많이 걸리는 경우 비정상으로 판단하고 리밸런싱을 시작
- 기본값은 300000(5분)
isolation.level: 트랜잭션 프로듀서가 레코드를 트랜잭션 단위로 보낼 경우 사용read_committed: 커밋이 완료된 레코드만 읽는다read_uncommitted (default): 커밋 여부와 관계없이 파티션에 있는 모든 레코드를 읽는다
동기(명시적) 오프셋 커밋
poll() 메서드가 호출된 이후 commitSync() 메서드를 호출하여 동기(명시적) 오프셋 커밋을 수행할 수 있다
SyncCommitConsumer
public class SyncCommitConsumer {
private final static Logger logger = LoggerFactory.getLogger(SyncCommitConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
// 명시적 오프셋 커밋
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// 지속적인 반복 호출을 위해 무한 루프를 생성한다.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
consumer.commitSync(); // 명시적 커밋을 동기적으로 수행
}
}
}
}- commitSync()는 poll() 메서드로 받은 가장 마지막 레코드의 오프셋을 기준으로 커밋
- 동기 오프셋 커밋을 사용할 경우 poll() 메서드로 받은 모든 레코드의 처리가 끝난 이후 commitSync() 메서드를 호출해야 한다.
- 동기 커밋의 경우 브로커로 커밋을 요청한 이후에 커밋이 완료되기까지 기다린다.
- 브로커로부터 컨슈머 오프셋 커밋이 완료되었음을 받기까지 컨슈머는 데이터를 다 처리하지 않고 기다리기 때문에 자동 커밋이나 비동기 오프셋 커밋보다 동일 시간당 데이터 처리량이 적다
만약 개별 레코드 단위로 매번 오프셋을 커밋하고 싶다면, commitSync() 메서드에 Map<TopicPartition, OffsetAndMetadat> 인스턴스를 파라미터로 넣으면 된다.
public class SyncOffsetCommitConsumer {
private final static Logger logger = LoggerFactory.getLogger(SyncOffsetCommitConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
// 현재 처리한 오프셋을 매번 커밋하기 위해 파라미터 추가
// TopicPartition: 토픽과 파티션 정보가 담김 (키)
// OffsetAndMetadata: 오프셋 정보가 담김 (값)
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
// 처리 완료한 레코드의 정보를 토대로 Map<TopicPartition, OffsetAndMetadata> 인스턴스에 키/값 넣기
// 주의할 점은 현재 처리한 오프셋에 1을 더한 값을 커밋
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, null)
);
// 파라미터를 추가했으므로 해당 특정 토픽, 파티션의 오프셋이 매번 커밋됨
consumer.commitSync();
}
}
}
}비동기 오프셋 커밋
동기 오프셋 커밋을 사용할 경우 커밋 응답을 기다리는 동안 데이터 처리가 일시적으로 중단되기 때문에 더 많은 데이터를 처리하기 위해서 '비동기 오프셋 커밋'을 사용 할 수 있다. 비동기 오프셋 커밋은 commitAsync() 메서드를 호출하여 사용 가능하다.
비동기 오프셋은 커밋이 완료될 때까지 응답을 기다리지 않고 비동기로 응답을 받게 된다. 때문에 callback 함수를 파라미터로 받아서 결과를 얻을 수 있다.
public class AsyncCommitConsumer {
private final static Logger logger = LoggerFactory.getLogger(AsyncCommitConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// 지속적인 반복 호출을 위해 무한 루프를 생성한다.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
// commitAsync()에 callback 함수를 파라미터로 전달하여 커밋 응답을 비동기로 받는다.
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if (e != null) {
// map에는 오프셋 정보가 담겨있다.
logger.error("Commit failed for offsets {}", map, e);
System.err.println("Commit failed");
} else {
System.out.println("Commit success");
}
}
}); // 명시적 커밋을 동기적으로 수행
}
}
}
}OffsetCommitCallback는 commitAsync()의 응답을 받을 수 있도록 도와주는 콜백 인터페이스- 비동기로 받은 커밋 응답은 onComplete()를 통해 확인
- 정상적으로 커밋되었다면 exception 객체는 null
- Map<TopicPartition, OffsetAndMetadata> map: 커밋 완료된 오프셋 정보가 담긴 객체
리밸런스 리스너를 가진 컨슈머
- 컨슈머 그룹에서 컨슈머가 추가 또는 제거되면 파티션을 컨슈머에 재할당하는 과정인 리밸런스가 발생
- poll() 메서드를 통해 반환받은 데이터를 모두 처리하기 전에 리밸런스가 발생하면 데이터가 중복 처리될 수 있음
- poll() 메서드를 통해 받은 데이터 중 일부를 처리했으나 커밋하지 않았기 때문
- 리밸런스 발생 시 데이터를 중복 처리하지 않게 하기 위해서는 리밸런스 발생 시 처리한 데이터를 기준으로 커밋을 시도해야 함
- 리밸런스 발생을 감지하기 위해 카프카 라이브러리는
ConsumerRebalanceListener인터페이스를 지원
public class RebalanceListenerConsumer {
private final static Logger logger = LoggerFactory.getLogger(RebalanceListenerConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
private static KafkaConsumer<String, String> consumer;
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
// 리밸런스 발생 시 수동 커밋을 위해 false로 설정
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
consumer = new KafkaConsumer<>(configs);
// subscribe()의 두번째 파라미터로 리밸런스 리스너를 전달하여 설정할 수 있다
consumer.subscribe(Arrays.asList(TOPIC_NAME), new RebalanceListener());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
HashMap<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
// 해당 특정 토픽, 파티션의 오프셋이 매번 커밋된다.
currentOffset.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, null) // 현재 처리한 오프셋에 1을 더한 값을 커밋해야 한다.
);
consumer.commitSync(currentOffset);
}
}
}
private static class RebalanceListener implements ConsumerRebalanceListener {
// 리밸런스가 시작되기 전에 호출
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
logger.warn("Partitions are revoked");
consumer.commitSync();
}
// 리밸런스가 끝난 뒤 호출
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
logger.warn("Partitions are assigned");
}
}
}파티션 할당 컨슈머
- 컨슈머 운영 시 subscribe() 메서드를 사용하여 구독형태로 사용하는 것 외에도, 직접 파티션을 컨슈머에 명시적으로 할당하여 운영 가능
- 컨슈머가 어떤 토픽, 파티션을 할당할지 명시적으로 선언할 때는
assign()메서드 사용 - assign() 메서드는
TopicPartitions인스턴스를 지닌 자바 컬렉션 타입을 파라미터로 받음 - TopicPartitions: 카프카 라이브러리 내/외부에서 사용되는 토픽, 파티션의 정보를 담는 객체
- 컨슈머가 어떤 토픽, 파티션을 할당할지 명시적으로 선언할 때는
- subscribe() 메서드를 사용할 때와 다르게 컨슈머가 직접 특정 토픽, 특정 파티션에 할당되므로 리밸런싱하는 과정이 없다
- 컨슈머에 할당된 토픽과 파티션에 대한 정보는
assignment()메서드를 통해 확인 가능
public class AssignPartitionConsumer {
private final static Logger logger = LoggerFactory.getLogger(AssignPartitionConsumer.class);
private final static String TOPIC_NAME = "test";
private final static int PARTITION_NUMBER = 0;
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
private static KafkaConsumer<String, String> consumer;
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
consumer = new KafkaConsumer<>(configs);
// 파티션 명시적 할당
consumer.assign(Collections.singleton(new TopicPartition(TOPIC_NAME, PARTITION_NUMBER)));
// 컨슈머에 할당된 토픽과 파티션 정보 확인
Set<TopicPartition> assignedTopicPartition = consumer.assignment();
for (TopicPartition topicPartition : assignedTopicPartition) {
logger.info("{} - {}", topicPartition.topic(), topicPartition.partition());
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
HashMap<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
currentOffset.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, null)
);
consumer.commitSync(currentOffset);
}
}
}
}컨슈머의 우아한 종료(Graceful Shutdown)
- 컨슈머 애플리케이션은 안전하게 종료되어야 함
- 정상적으로 종료되지 않은 컨슈머는 세션 타임아웃이 발생할때까지 컨슈머 그룹에 남게 됨..
- 이로 인해 실제로는 종료되었지만 더는 동작하지 않는 컨슈머가 존재하기 때문에, 파티션의 데이터는 소모되지 못하고 컨슈머 랙이 증가
- 컨슈머 랙이 늘어나면 데이터 처리 지연 발생
- 컨슈머를 안전하게 종료하기 위해 wakeup() 메서드를 지원
- wakeup()이 실행된 이후 poll() 메서드가 호출되면
WakeupException예외가 발생 WakeupException예외를 받은 뒤에는 데이터 처리를 위해 사용한 자원을 해제하면 됨!
- wakeup()이 실행된 이후 poll() 메서드가 호출되면
- wakeup()은 셧다운 훅(shutdown hook)을 사용하여 호출하도록 한다
- 자바 애플리케이션의 경우 코드 내부에 셧다운 훅을 구현하여 안전한 종료를 명시적으로 구현 가능
- 셧다운 훅(shutdown hook): 사용자 또는 운영체제로부터 종료 요청을 받으면 실행하는 스레드
- 셧다운훅(kill -TERM 프로세스번호)가 발생하면, wakeup() 메서드가 호출되어 컨슈머를 안전하게 종료
public class SyncOffsetCommitShutdownHookConsumer {
private final static Logger logger = LoggerFactory.getLogger(SyncOffsetCommitShutdownHookConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
private static KafkaConsumer<String, String> consumer;
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
// 셧다운 훅 등록
Runtime.getRuntime().addShutdownHook(new ShutdownHook());
consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
}
}
} catch (WakeupException e) {
logger.warn("Wakeup consumer");
// 리소스 종료 처리
} finally {
consumer.close();
}
}
// ShutdownHook 구현
private static class ShutdownHook extends Thread {
@Override
public void run() {
logger.info("Shutdown Hook");
consumer.wakeup();
}
}
}카프카 클라이언트(Kafka Client) - 어드민 API
카프카 클라이언트에서는 내부 옵셔들을 설정하거나 조회하기 위해 AdminClient 클래스를 제공한다. 이를 사영하면 클러스터의 옵션과 관련된 부분을 커맨드를 통해 직접 설정할 필요 없이 자동화할 수 있다. 대표적인 활용 예시는 다음과 같다.
SimpleAdminClient
public class SimpleAdminClient {
private final static Logger logger = LoggerFactory.getLogger(SimpleAdminClient.class);
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) throws Exception {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
AdminClient admin = AdminClient.create(configs);
// == 1. 브로커 정보 조회 ==
logger.info("== Get broker information");
for (Node node : admin.describeCluster().nodes().get()) {
// 각 브로커(노드)를 가져온다.
logger.info("Node : {}" + node);
ConfigResource cr = new ConfigResource(ConfigResource.Type.BROKER, node.idString());
// 브로커의 설정 정보를 가져온다.
DescribeConfigsResult describeConfigs = admin.describeConfigs(Collections.singleton(cr));
describeConfigs.all().get().forEach((broker, config) -> {
config.entries().forEach(entry -> logger.info(entry.name() + "= " + entry.value()));
});
}
// == 2. default 파티션 개수 조회 ==
logger.info("== Get default num.partitions");
for (Node node : admin.describeCluster().nodes().get()) {
ConfigResource cr = new ConfigResource(ConfigResource.Type.BROKER, node.idString());
DescribeConfigsResult describeConfigs = admin.describeConfigs(Collections.singleton(cr));
Config config = describeConfigs.all().get().get(cr);
Optional<ConfigEntry> optionalConfigEntry = config.entries().stream().filter(v -> v.name().equals("num.partitions")).findFirst();
ConfigEntry numPartitionConfig = optionalConfigEntry.orElseThrow(Exception::new);
logger.info("{}", numPartitionConfig.value());
}
// == 3. 토픽 리스트 조회 ==
logger.info("== Topic list");
for (TopicListing topicListing : admin.listTopics().listings().get()) {
logger.info("{}", topicListing.toString());
}
// == 4. 컨슈머 그룹 리스트 조회 ==
logger.info("== Consumer group list");
ListConsumerGroupsResult listConsumerGroups = admin.listConsumerGroups();
listConsumerGroups.all().get().forEach(v -> {
logger.info("{}", v);
});
// == 5. 토픽 정보 조회 ==
String targetTopicName = "test";
Map<String, TopicDescription> topicInformation = admin
.describeTopics(Collections.singletonList(targetTopicName)).all().get();
logger.info("{}", topicInformation);
// 종료 메서드 명시적 호출
admin.close();
}
}
다음 포스팅에 이어서 카프카 스트림즈, 카프카 커넥트, 카프카 미러메이커2에 대해 알아보겠다!
'Data Infra' 카테고리의 다른 글
| [Apache Kafka] 카프카 프로듀서 상세 개념 (2) | 2024.12.11 |
|---|---|
| [Apache Kafka] 토픽과 파티션 상세 개념 (2) | 2024.12.11 |
| [Apache Kafka] 카프카 스트림즈, 카프카 커넥트, 카프카 미러메이커2 (2) | 2024.12.10 |
| [Apache Kafka] 카프카 설치와 커맨드 라인 툴 (3) | 2024.12.04 |
| [Apache Kafka] 카프카의 탄생과 미래 (1) | 2024.12.03 |