
본 게시글은 '아파치 카프카 애플리케이션 프로그래밍 with 자바'를 읽고 개인적으로 정리한 내용입니다
카프카 스트림즈 - 개요
- 카프카 스트림즈(Kafka Streams): 토픽에 적재된 데이터를 상태기반(stateful) 또는 비상태기반(stateless)으로 실시간 변환하여 다른 토픽에 적재하는 라이브러리
- 아파치 스파크(Apache Spark), 아파치 플링크(Apache Flink), 아파치 스톰(Apache Storm), 플루언트디(Fluentd)와 같은 다양한 오픈소스 애플리케이션도 있으나, 카프카 스트림즈 사용 권장
- 카프카 스트림즈를 사용해야 하는 이유
- 카프카에서 공식적으로 지원하는 라이브러리 -> 카프카 클러스터와 완벽 호환
- 스트림 처리에 필요한 편리한 기능들(신규 토픽 생성, 상태 저장, 데이터 조인 등)을 제공
- 스트림즈 애플리케이션 혹은 카프카 브로커 장애 발생 시에도 '정확히 한 번(exactly once)' 할 수 있도록 장애 허용 시스템(fault tolerant system)이 있어 데이터 처리 안정성 뛰어남
- '프로듀서 + 컨슈머'를 조합해서 사용하지 않고 스트림즈를 사용하는 이유?
- 프로듀서&컨슈머 조합으로 가능한 것은 대부분의 경우 스트림즈로도 가능
- 스트림 데이터 처리에 있어 다양한 기능을 스트림즈DSL로 제공 & 필요에 따라 프로세서 API를 사용하여 기능 확장 가능
- 스트림즈가 가능한 것은 프로듀서&컨슈머 조합으로 완벽 수행 불가능
- 단 한번의 데이터 처리, 장애 허용 시스템 등의 특징들
- => 스트림즈가 불가능한 기능 구현 시에만 프로듀서 + 컨슈머 조합 사용하자
- ex) 소스 토픽(사용하는 토픽)과 싱크 토픽(저장하는 토픽)의 카프카 클러스터가 서로 다른 경우
- 프로듀서&컨슈머 조합으로 가능한 것은 대부분의 경우 스트림즈로도 가능
스트림즈 애플리케이션 내부 구조
- 스트림즈 애플리케이션은 내부적으로 스레드를 1개 이상 생성 가능, 스레드는 1개 이상의 태스크(task)를 가짐
- 태스크: 스트림즈 애플리케이션을 실행하면 생기는 데이터 처리 최소 단위
- 컨슈머의 병렬 처리를 위해 컨슈머 그룹으로 이루어진 컨슈머 스레드를 여러 개 실행하는 것과 유사
- 컨슈머 스레드를 늘리는 것처럼 스트림즈 스레드(또는 프로세스) 수를 늘려 처리량을 늘릴 수 있음
- 실제 운영 환경에서는 안정성을 위해 2개 이상의 서버로 구성하여 스트림즈 애플리케이션을 운영
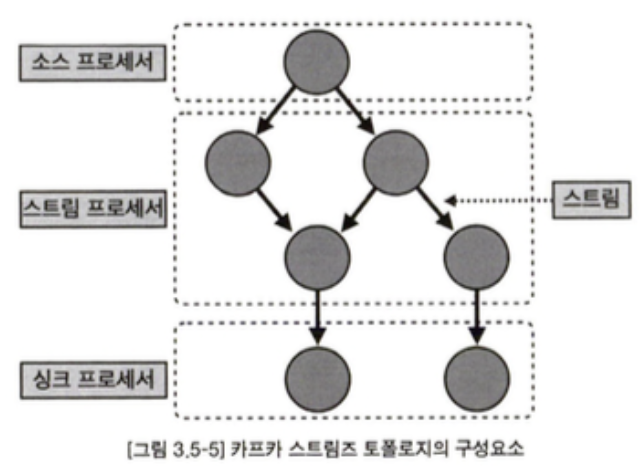
- 토폴로지(topology): 2개 이상의 노드들과 선으로 이루어진 집합
- 토폴로지 종류: 링형(ring), 트리형(tree), 성형(star) 등
- 스트림즈에서 사용하는 토폴로지는 트리 형태와 유사 -> 계층 구조
- 프로세서(processor): 카프카 스트림즈에서 토폴로지를 이루는 노드
- 소스 프로세서: 하나 이상의 토픽에서 데이터를 가져오는 역할을 하는 노드로, 데이터를 처리하기 위해 최초로 선언해야 함
- 스트림 프로세서: 다른 프로세서가 반환한 데이터를 처리하는 역할을 하는 노드로, 변환이나 분기 처리와 같은 로직을 수행
- 싱크 프로세서: 데이터를 특정 카프카 토픽으로 저장하는 역할을 하는 노드로, 스트림즈 처리된 데이터의 최종 종착지
- 스트림(stream): 노드와 노드를 이은 선으로, 토픽의 데이터를 뜻함 (= 레코드)
스트림즈DSL & 프로세서 API
- 스트림즈DSL을 사용하여 스트림 프로세싱에 쓰일 만한 다양한 기능들을 자체 API로 만들어 놓아 대부분의 변환 로직을 어렵지 않게 개발 가능
- 스트림즈DSL에서 제공하지 않는 일부 기능들의 경우 프로세서 API를 사용하여 구현
- 스트림즈DSL로 구현하는 데이터 처리 예시
- 메시지 값을 기반으로 토픽 분기 처리
- 지난 10분간 들어온 데이터의 수 집계
- 토픽과 달느 토픽의 결합으로 새로운 데이터 생성
- 프로세서 API로 구현하는 데이터 처리 예시
- 메시지 값의 종류에 따라 토픽을 가변적으로 전송
- 일정한 시간 간격으로 데이터 처리
여기서는 매우 기본적인 내용만 다루므로, 자세한 내용을 알고싶다면 'Kafka Streams In Action - 윌리엄 베젝'을 읽어보자
카프카 스트림즈 - 스트림즈DSL
KStream- 레코드의 흐름을 표현한 것으로 메시지 키와 메시지 값으로 구성됨
- KStream으로 데이터 조회 시 토픽에 존재하는(또는 KStream에 존재하는) 모든 레코드 출력
- KStream = 컨슈머로 토픽을 구독하여 사용하는 것
KTable- KStream과 다르게 메시지 키를 기준으로 묶어서 사용
- 모든 레코드가 아닌, 유니크한 메시지 키를 기준으로 가장 최신(가장 최근에 추가된) 레코드를 사용
- 새로 데이터를 적재할 때 동일한 메시지 키가 존재할 경우, 데이터가 업데이트 되었다고 볼 수 있음
- KTable로 선언된 토픽은 1개 파티션이 1개 태스크에 할당
GlobalKTable- KTable과 동일하게 메시지 키를 기준으로 묶어서 사용
- GlobalKTable로 선언된 토픽은 모든 파티션 데이터가 각 태스크에 할당되어 사용
- GlobalKTable을 사용하는 가장 좋은 예: KStream & KTable이 데이터 조인을 수행할 때
조인을 위한 코파티셔닝 & 리파티셔닝
- KStream과 KTable을 조인하려면 반드시 코파티셔닝(co-partitioning)되어 있어야 함
- 코파티셔닝: 조인 할 2개 데이터의 파티션 개수와 파티셔닝 전략을 동일하게 맞추는 것
- 코파티셔닝 되어 있다면,(= 파티션 개수와 파티셔닝 전략이 동일하다면) 같은 메시지 키를 가진 데이터가 동일한 테스크의 들어가는 것을 보장
- 이를 통해 KStream과 KTable의 메시지 키가 동일할 경우 조인 수행 가능
- 문제는 조인을 수행하려는 토픽들이 코파티셔닝 되어있음을 보장할 수 없다는 것..
- 코파티셔닝 되어 있지 않은 2개의 토픽을 조인 시도하면
TopologyException발생 - 코파티셔닝 되어 있지 않다면 KStream 또는 KTable을 리파티셔닝(repartitioning)하는 과정을 거쳐야 함
- 코파티셔닝 되어 있지 않은 2개의 토픽을 조인 시도하면
- 리파티셔닝: 새로운 토픽에 새로운 메시지 키를 가지도록 재배열 하는 과정
- 리파티셔닝을 거쳐서 KStream과 KTable에서 사용하는 2개의 토픽이 코파티셔닝 되도록 할 수 있음
- 하지만, 리파티셔닝은 비용이 매우 큰 작업
- 토픽에 기존 데이터를 중복해서 생성하고 파티션을 재배열하기 위해 프로세싱하는 과정도 거쳐야 함
- 리파티셔닝을 통한 코파티셔닝의 대안으로, KTable을 GlobalKTable로 선언하여 사용하는 방법이 있다!
- GlobalKTable은 모든 태스크에 동일하게 공유되어 사용되기 때문에, 코파티셔닝되지 않은 KStream과 데이터 조인 가능
- 다만, GloablKTable 사용 시 스트림즈 사용량이 증가하고 네트워크, 브로커에 부하 발생
- 각 태스크마다 GlobalKTable로 정의된 모든 데이터를 저장하고 사용하기 때문
- 되도록이면 작은 용량의 데이터일 경우에만 사용
- 많은 양의 데이터일 경우 리파티셔닝을 통해 KTable 사용
스트림즈DSL 주요 옵션
- 필수 옵션
bootstrap.servers: 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 호스트 이름:포트를 1개 이상 작성application.id: 스트림즈 애플리케이션을 구분하기 위한 고유한 아이디 설정
- 선택 옵션
default.key.serde: 레코드의 메시지 키를 직렬화, 역직렬화 하는 클래스 지정- 기본값은
Serdes.ByteArray().getClass().getName()
- 기본값은
default.value.serde: 레코드의 메시지 값을 직렬화, 역직렬화 하는 클래스 지정- 기본값은
Serdes.ByteArray().getClass().getName()
- 기본값은
num.stream.threads: 스트림 프로세싱 실행 시 실행될 스레드 개수를 지정- 기본값은 1
state.dir: rocksDB 저장소가 위치할 디렉토리 지정- rocksDB: 고성능의 key-value DB로, 카프카 스트림즈가 상태기반 데이터 처리를 할 때 사용하는 로컬 저장소
- 기본값은
/tmp/kafka-streams - 스트림즈 애플리케이션을 상용 운영 시에는
/tmp디렉토리가 아닌 별도로 관리되는 디렉토리로 지정 필요
이제 스트림즈DSL로 스트림즈 애플리케이션을 구현하는 예시를 봐보자!
스트림즈DSL - stream(), to()
특정 토픽의 데이터를 다른 토픽으로 전달하는 아주 간단한 스트림 프로세싱을 스트림즈DSL로 구현해보자
- stream(): 특정 토픽을 KStream 형태로 가져옴
- to(): KStream의 데이터를 특정 토픽으로 저장
먼저 build.gradle에 의존성을 추가한다
dependencies {
implementation 'org.apache.kafka:kafka-clients:2.5.0'
implementation 'org.slf4j:slf4j-simple:2.0.13'
implementation 'org.apache.kafka:kafka-streams:3.2.0'
testImplementation platform('org.junit:junit-bom:5.10.0')
testImplementation 'org.junit.jupiter:junit-jupiter'
}M1 칩 사용 시 kafka-streams 라이브러리의 rocksDB 버전이 6.29.4.1 이상이어야 한다. kafka-streams 2.5.0 + rocksDB 6.29.4.1을 사용할 경우 2개 버전이 호환되지 않으므로 kafka-streams 라이브러리의 버전을 3.2.0 이상으로 올려주었다
public class SimpleStreamApplication {
private static String APPLICATION_NAME = "streams-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String STREAM_LOG = "stream_log";
private static String STREAM_LOG_COPY = "stream_log_copy";
public static void main(String[] args) {
Properties configs = new Properties();
// 스트림즈 애플리케이션은 필수로 애플리케이션 아이디를 지정해야 한다
configs.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
configs.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 메시지 키와 메시지 값의 직렬화 및 역직렬화 방식을 지정한다.
configs.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
configs.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// StreamBuilder는 스트림 토폴로지를 정의하기 위한 용도로 사용된다.
StreamsBuilder builder = new StreamsBuilder();
// stream_log 토픽으로부터 KSteram 객체 생성한다는 의미
// 외에도 KTable을 만드는 table(), GlobalKTable을 만드는 globalTable() 메서드도 있다.
// stream(), table(), globalTable()은 최초의 토픽 데이터를 가져오는 '소스 프로세서'이다.
KStream<String, String> streamLog = builder.stream(STREAM_LOG);
// stream_log 토픽을 담은 KStream 객체를 stream_log_copy 토픽으로 전송한다는 의미 ('싱크 프로세서')
streamLog.to(STREAM_LOG_COPY);
// 지금까지 StreamBuilder로 정의한 토폴로지에 대한 정보와 옵션을 파라미터로 KafkaStreams 인스턴스를 생성하고, start()로 실행한다.
KafkaStreams streams = new KafkaStreams(builder.build(), configs);
streams.start();
}
}- 당연히 애플리케이션 실행 전에 먼저 토픽(stream_log, stream_log_copy)을 생성해주어야 한다. 이 부분은 위에서 많이 다뤘으므로 생략한다.
- 애플리케이션 실행 이후 stream_log 토픽에 데이터를 저장하면, stream_log_copy로 그대로 전송되어 저장된다(복사)
- 각각 커맨드 라인을 통해 수행해보자
스트림즈DSL - filter()
메시지 키 또는 메시지 값을 필터링하여 특정 조건에 맞는 데이터를 골라낼 때는 filter() 메서드를 사용하자.
- filter(): 스트림즈DSL에서 사용 가능한 필터링 스트림 프로세서
토픽으로 들어온 문자열 데이터 중 문자열의 길이가 5보다 큰 경우만 필터링 하는 스트림즈 애플리케이션을 구현해보자
public class StreamsFilter {
private static String APPLICATION_NAME = "streams-filter-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String STREAM_LOG = "stream_log";
private static String STREAM_LOG_COPY = "stream_log_filter";
public static void main(String[] args) {
Properties configs = new Properties();
// 스트림즈 애플리케이션은 필수로 애플리케이션 아이디를 지정해야 한다
configs.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
configs.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 메시지 키와 메시지 값의 직렬화 및 역직렬화 방식을 지정한다.
configs.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
configs.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> streamLog = builder.stream(STREAM_LOG);
// 데이터를 필터링하는 filter() 메서드는 자바의 함수형 인터페이스인 Predicate를 파라미터로 받는다
// 여기서는 메시지 키와 메시지 값에 대한 조건을 나타내고, value.lenght > 5로 메시지 값의 길이가 5보다 큰 경우만 필터링하도록 작성했다
KStream<String, String> filteredStream = streamLog.filter((key, value) -> value.length() > 5);
filteredStream.to(STREAM_LOG_COPY);
// 지금까지 StreamBuilder로 정의한 토폴로지에 대한 정보와 옵션을 파라미터로 KafkaStreams 인스턴스를 생성하고, start()로 실행한다.
KafkaStreams streams = new KafkaStreams(builder.build(), configs);
streams.start();
}
}- 역시 stream_log 토픽으로 데이터를 넣어보면서 stream_log_copy에 필터링된 데이터가 적재되는지 확인해보자
스트림즈DSL - KTable과 KStream을 join()
- KTable과 KStream은 메시지 키를 기준으로 조인 가능
- 대부분의 데이터베이스는 정적으로 저장된 데이터를 조인하여 사용하지만, 카프카에서는 실시간으로 들어오는 데이터들을 조인 가능
- 사용자의 이벤트 데이터를 데이터베이스에 저장하지 않고도 조인하여 스트리밍 처리가 가능
- KTable과 KStream을 조인할 때 가장 중요한 것은 코파티셔닝 여부
- 토픽 생성 시 동일한 파티션 개수, 동일한 파티셔닝 전략을 사용하도록 설정해주자
KStream, KTable, GloablKTable 모두 동일한 토픽이다. 다만, 스트림즈 애플리케이션 내부에서 사용할 때 메시지 키와 메시지 값을 사용하는 형태를 구분할 뿐이다
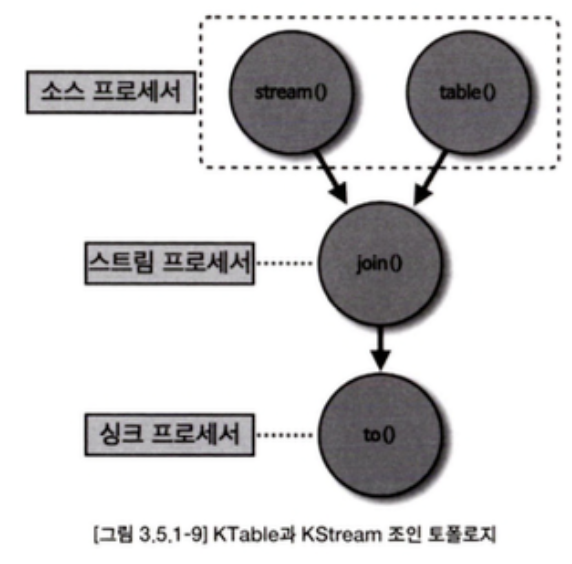
KTable과 KStream을 소스 프로세서로 가져와서 조인을 수행하는 스트림 프로세서를 거쳐, 특정 토픽에 싱크 프로세서로 저장하는 로직을 구현해보자
public class KStreamJoinKTable {
private static String APPLICATION_NAME = "streams-join-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String ADDRESS_TABLE = "address";
private static String ORDER_STREAM = "order";
private static String ORDER_JOIN_STREAM = "order_join";
public static void main(String[] args) {
Properties configs = new Properties();
// 스트림즈 애플리케이션은 필수로 애플리케이션 아이디를 지정해야 한다
configs.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
configs.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 메시지 키와 메시지 값의 직렬화 및 역직렬화 방식을 지정한다.
configs.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
configs.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
// address 토픽은 KTable로 가져오기 위해 table() 메서드를 소스 프로세서로 사용
KTable<String, String> addressTable = builder.table(ADDRESS_TABLE);
// order 토픽은 KStream으로 가져오기 위해 stream() 메서드를 소스 프로세서로 사용
KStream<String, String> orderStream = builder.stream(ORDER_STREAM);
// 조인을 위해 KStream 인스턴스에 정의되어 있는 join() 메서드를 사용하며, 첫 번째 파라미터로 조인할 KTable 인스턴스를 넣는다.
// KStream과 KTable에서 동일한 메시지 키를 가진 데이터를 찾았을 경우 각각의 메시지 값을 조합해서 어떤 데이터를 만들지 정의한다.
orderStream.join(addressTable, (order, address) -> order + " send to " + address)
.to(ORDER_JOIN_STREAM);
KafkaStreams streams = new KafkaStreams(builder.build(), configs);
streams.start();
}
}
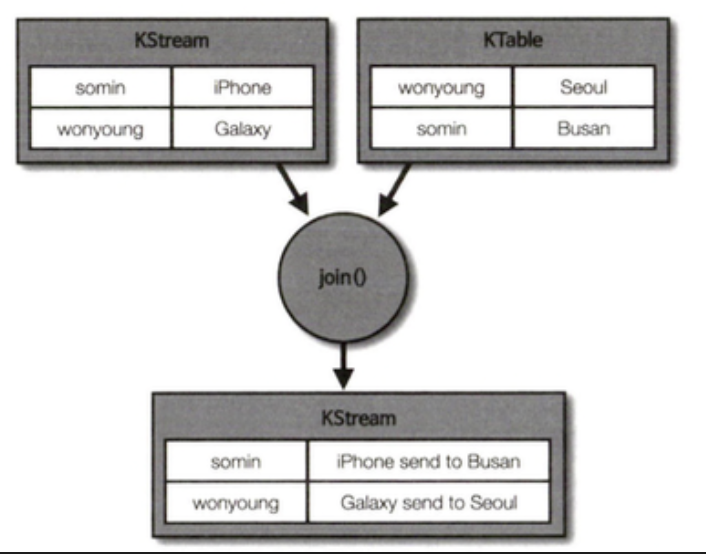
- address 토픽에 키:값 형식으로 데이터를 넣고, order 토픽에도 키:값 형식으로 데이터를 넣어 위 애플리케이션을 실행해보자
- order_join 토픽을 확인하면 같은 키의 경우 실시간으로 조인이 수행되어 해당 키 값에 대한 값이
order + " send to " + address형태로 저장되어 있으 것이다 - 만약 사용자의 주소(키)가 변경되는 경우 어떻게 될까?
- KTable은 동일한 메시지 키가 들어올 경우 가장 마지막의 레코드를 유효한 데이터로 보기 때문에 가장 최근에 바뀐 주소로 조인을 수행할 것
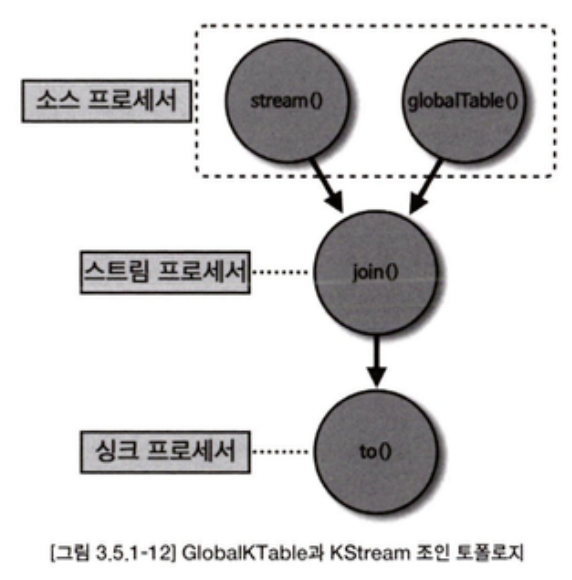
스트림즈DSL - GlobalKTable과 KStream을 join()
- 코파티셔닝되어 있지 않은 토픽을 조인해야 할 때 사용 가능한 방법 2가지
- 리파티셔닝을 수행한 후, 코파티셔닝된 상태로 join()
- KTable로 사용하는 토픽을 GlobalKTable로 선언하여 사용
- 여기서는 GlobalKTable을 사용해보기 위해 일부러 코파티셔닝되지 않은 2개의 토픽을 사용하겠다
public class KStreamJoinGlobalKTable {
private static String APPLICATION_NAME = "global-table-join-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String ADDRESS_GLOBAL_TABLE = "address_v2";
private static String ORDER_STREAM = "order";
private static String ORDER_JOIN_STREAM = "order_join";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
configs.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// address_v2 토픽을 GlobalKTable로 지정한다.
configs.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
configs.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
GlobalKTable<Object, Object> addressGlobalTable = builder.globalTable(ADDRESS_GLOBAL_TABLE);
KStream<String, String> orderStream = builder.stream(ORDER_STREAM);
// GlobalKTable을 조인하기 위해 join() 메서드를 사용한다. GloablKTable을 첫 번째 파라미터로 넘겨준다.
orderStream.join(addressGlobalTable,
// GlobalKTable은 KTable의 조인과 다르게 레코드를 매칭할 때, KStream의 멧지 키와 메시지 값 둘 다 사용할 수 있다. 여기서는 KStream의 키를 GlobalKTable의 메시지 키와 매칭하도록 했다.
(orderKey, orderValue) -> orderKey,
(order, address) -> order + " send to " + address)
.to(ORDER_JOIN_STREAM);
KafkaStreams streams = new KafkaStreams(builder.build(), configs);
streams.start();
}
}- GlobalKTable로 선언한 토픽은 토픽에 존재하는 모든 데이터를 태스크마다 저장하고 조인 처리를 수행하는 점이 KTable과 다르다
- 또한, 조인 수행 시 KStream의 메시지 키뿐만 아니라 메시지 값을 기준으로도 매칭하여 조인할 수 있다는 점도 다르다
카프카 스트림즈 - 프로세서 API
- 프로세서 API는 스트림즈DSL보다 투박한 코드를 가지지만 토폴로지를 기준으로 데이터를 처리한다는 관점에서는 동일한 역할을 함
- 스트림즈DSL에서 제공하지 않는 추가적인 상세 로직의 구현이 필요하면 프로세서 API를 사용
- 프로세서 API에서는 스트림즈DSL에서 사용했던 KStream, KTable, GlobalKTable 개념이 없음에 주의
토픽의 문자열 길이가 5 이상인 데이터를 필터링해서 다른 토픽으로 저장하는 애플리케이션을 개발해보자
FilterProcessor
// 스트림 프로세서 클래스를 생성하기 위해서는 Processor 또는 Transformer 인터페이스를 상속
public class FilterProcessor implements Processor<String, String> {
// 프로세서에 대한 정보를 담고 있는 객체
// 현재 스트림 처리 중인 토폴로지의 토픽 정보, 애플리케이션 아이디를 조회 가능
private ProcessorContext context;
// 스트림 프로세서의 생성자
@Override
public void init(ProcessorContext processorContext) {
this.context = processorContext;
}
// 실질적인 프로세싱 로직이 들어가는 부분
// 1개의 레코드를 받는 것을 가정하여 데이터를 처리
// 메시지 키, 메시지 값을 파라미터로 받는다
@Override
public void process(String key, String value) {
if (value.length() > 5) {
// 필터링 된 데이터를 다음 토폴로지(다음 프로세서)로 넘긴다.
context.forward(key, value);
}
// 처리가 완료된 이후 명시적으로 데이터가 처리되었음을 알린다.
context.commit();
}
// 프로세서가 종료되기 전에 호출되는 메서드
// 보통 프로세싱을 위해 사용한 리소스를 해제하는 구문을 넣는다
@Override
public void close() {
}
}
SimpleKafkaProcessor
public class SimpleKafkaProcessor {
private static String APPLICATION_NAME = "processor-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String STREAM_LOG = "stream_log";
private static String STREAM_LOG_FILTER = "stream_log_filter";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
configs.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
configs.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// Topology 클래스는 프로세서 API를 사용한 토폴로지를 구성하기 위해 사용된다
Topology topology = new Topology();
topology.addSource("Source", STREAM_LOG) // stream_log 토픽을 소스 프로세서로 가져오기 위해 addSource() 메서드를 사용 (파라미터는 '소스 프로세서 이름', '대상 토픽 이름' 순)
.addProcessor("Process", FilterProcessor::new, "Source") // 스트림 프로세서를 사용하기 위해 addProcessor() 메서드를 사용 (파라미터는 '스트림 프로세서 이름', '사용자 정의 프로세서 인스턴스' , '부모 노드' 순)
.addSink("Sink", STREAM_LOG_FILTER, "Process"); // stream_log_filter를 싱크 프로세서로 사용하여 데이터를 저장하기 위해 addSink() 메서드를 사용 (파라미터는 '싱크 프로세서 이름', '저장할 토픽 이름', '부모 노드' 순)
KafkaStreams streaming = new KafkaStreams(topology, configs);
streaming.start();
}
}카프카 커넥트(Kafka Connect)
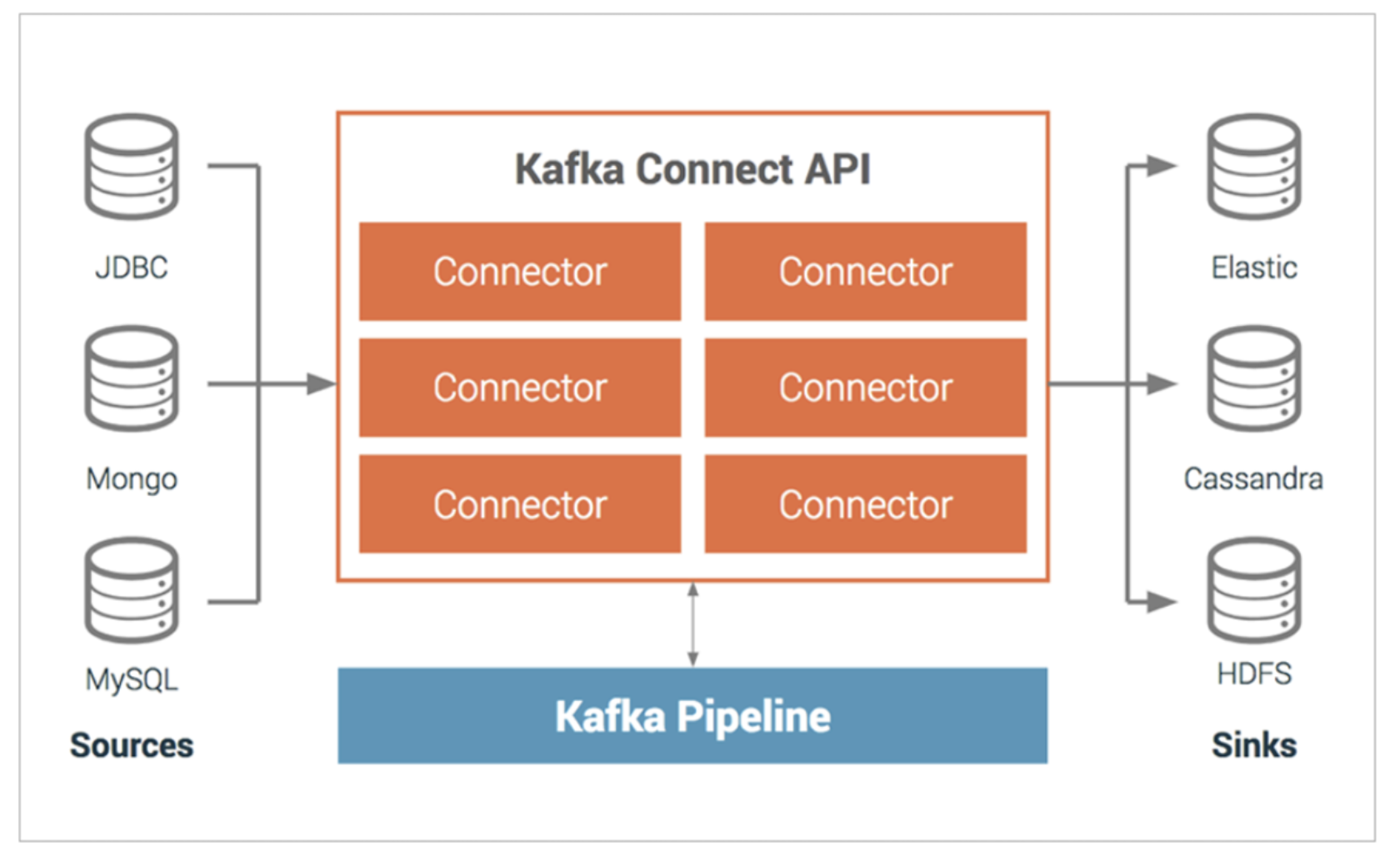
- 파이프라인을 생성할 때 프로듀서와 컨슈머 애플리케이션을 사용하는 것이 일반적이지만, 이러한 작업이 반복되면 비효율적이다.
- 이러한 문제를 해결하기 위해 '카프카 커넥트'가 등장
- 카프카 커넥트(Kafka Connect): 데이터 파이프라인 생성 시 반복 작업을 줄이고 효율적인 전송을 이루기 위한 애플리케이션
- 커넥트는 특정한 작업 형태를 템플릿으로 만들어놓은 커넥터(connector)를 실행함으로써 반복 작업을 줄일 수 있음
- 파이프라인 생성 시 자주 반복되는 값들(토픽 이름, 파일 이름, 테이블 이름 등)을 파라미터로 받는 커넥터를 코드로 작성하면 이후 파이프라인 실행 시 코드를 작성할 필요가 없어짐
- 커넥터는 각 커넥터가 가진 고유한 설정값을 입력받아서 데이터를 처리
커넥터의 종류
- Kafka Connect는 두 가지 커넥터를 사용하여 데이터를 처리
- 소스 커넥터(Source Connector): 외부 소스에서 데이터를 가져와 카프카로 전송(프로듀서 역할)
- 싱크 커넥터(Sink Connector): 카프카에서 데이터를 읽어 타겟 시스템으로 전송(컨슈머 역할)
- ex) 파일 소스 커넥터(File Source Connector)는 파일에서 데이터를 읽어와 Kafka 토픽에 저장 & 파일 싱크 커넥터(File Sink Connector)는 Kafka 토픽의 데이터를 파일로 저장
- 파일 외에도 일정한 프로토콜을 가진 소스 애플리케이션이나 싱크 애플리케이션이 있다면 커넥터를 통해 카프카로 데이터를 보내거나 카프카에서 데이터를 가져올 수 있음
- MySQL, S3, MongoDB 등과 같은 다양한 저장소와 연동할 수 있는 커넥터들이 제공됨
- 카프카 2.6에 포함된 커넥트를 실행할 경우 미러메이커2 커넥터, 파일 싱크 커넥터, 파일 소스 커넥터가 기본 플러그인으로 제공됨
- 외에 추가적인 커넥터를 사용하고 싶다면 플러그인 형태로 커넥터 jar 파일을 추가하여 사용 가능
- HDFS 커넥터, AWS S3 커넥터, JDBC 커넥터, 엘라스틱서치 커넥터 등 100개가 넘는 오픈소스 커넥터들이 있으며 이들을 다운받아 사용 가능
데이터 처리: 컨버터 & 트랜스폼
- 커넥트에 커넥터 생성 명령을 내리면 커넥트는 내부에 커넥터와 태스크를 생성
- 커넥터는 태스크들을 관리
- 태스크: 커넥터에 종속되는 개념으로 실질적인 데이터 처리를 함
- 데이터 처리가 정상적인지 확인하기 위해서는 각 태스크의 상태를 확인해야 함
- 데이터 처리 지원 옵션
- 컨버터(Converter): 데이터를 전송하기 전에 스키마를 변경하는 기능 수행
- 기본적으로 JsonConverter, StringConverter, ByteArrayConverter 지원
- 필요에 따라 커스텀 컨버터를 작성하여 사용 가능
- 트랜스폼(Transform): 메시지 단위로 데이터를 변환하는 기능 수행
- ex) 특정 데이터를 삭제, 특정 필드를 추출
- 기본 제공 트랜스폼 기능으로는 Cast, Drop, ExtractField 등이 있음
- 컨버터(Converter): 데이터를 전송하기 전에 스키마를 변경하는 기능 수행
커넥트 실행 방법 - 단일 모드 커넥트 (Standalone Mode Kafka Connect)
- 커넥트를 실행하는 방법은 크게 2가지로, 단일 모드 커넥트와 분산 모드 커넥트가 있다.
- 단일 모드 커넥트: 단일 애플리케이션(1개 프로세스)으로 실행
- 고가용성 X -> 단일 장애점(Single Point Of Failure, SPOF)이 될 수 있음
- 주로 개발환경이나 중요도가 낮은 파이프라인을 운영할 때 사용
- 단일 모드 실행 방법
- connect-standalone.properties 파일(커넥트 설정 파일) 설정
- 이 파일은 카프카 커넥트의 기본 설정을 담고 있음
- kafka 설치 디렉토리의 config 폴더에 위치
- 설정 파일 내용은 아래 코드 블럭에서 다룬다
- 커넥터 설정 파일 작성
- 실제로 데이터를 처리할 커넥터 설정 파일을 작성
- ex) 파일 소스 커넥터를 사용하려면 connect-file-source.properties 파일을 작성하여 파일 경로와 토픽 이름 정의
- connect-standalone.properties 파일(커넥트 설정 파일) 설정
connect-standalone.properties
...
# 커넥트와 연동할 카프카 클러스터의 호스트와 포트 작성. 2개 이상의 정보는 콤마로 구분
bootstrap.servers=localhost:9092
# 데이터를 카프카에 저장할 때 혹은 카프카에서 데이터를 가져올 때 변환하는 데에 사용
# JsonConverter, StringConverter, BytesArrayConverter 기본 지원
# 스키마 형태를 사용하고 싶지 않다면 enable=false로 두기
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 단일 모드 커넥트는 '로컬 파일에' 오프셋 정보를 저장
# 이 오프셋 정보는 소스 커넥터 또는 싱크 커넥터가 데이터 처리 시점을 저장하기 위해 사용
# 해당 정보는 데이터를 처리하는 데에 있어 중요한 역할을 하므로 다른 사용자나 시스템이 접근 못하게 해야 함
offset.storage.file.filename=/tmp/connect.offsets
# 태스크가 처리 완료한 오프셋을 커밋하는 주기 설정
offset.flush.interval.ms=10000
# 오픈소스로 다운 받았거나 직접 개발한 커넥터의 jar 파일이 위치하는 디렉토리 주소 입력
# 2개 이상의 디렉토리를 콤마로 구분하여 입력
# 커넥터 외에도 컨버터, 트랜스폼도 플러그인으로 추가 가능
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
connect-file-source.properties
# 커넥터 이름 지정. 이름은 유니크해야 함
name=local-file-source
# 사용할 커넥터의 클래스 이름 지정
# 여기서는 카프카에서 기본으로 제공하는 FileStreamSource 클래스 지정
connector.class=FileStreamSource
# 커넥터로 실행할 태스크 개수 지정
# 태스크 개수를 늘려서 병렬처리 가능
tasks.max=1
# 읽을 파일의 위치 지정
file=test.txt
# 읽은 파일의 데이터를 저장할 토픽의 이름 지정
topic=connect-test
이렇게 커넥트 설정 파일과 커넥터 설정 파일을 작성한 후, 다음의 커맨드를 통해 단일 모드 커넥트를 실행할 수 있다
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties커넥트 실행 방법 - 분산 모드 커넥트 (Distributed Mode Kafka Connect)
- 분산 모드 커넥트: 여러 서버에서 클러스터 형태로 실행되며, 주로 상용 환경과 대규모 데이터 파이프라인에서 사용
- 다수의 서버로 구성되어 고가용성을 지원
- 일부 커넥트가 이슈로 인해 중단되더라도 나머지 커넥트가 파이프라인을 지속적으로 처리 가능
- 데이터 처리량이 증가하면 서버를 추가하여 무중단 스케일 아웃 가능
- 다수의 서버로 구성되어 고가용성을 지원
- REST API를 사용하여 현재 실행 중인 커넥트의 커넥터 플러그인 종류, 태스크 상태, 커넥터 상태 등을 조회 가능
- 커넥트는 8083 포트로 호출 가능
- HTTP 메서드 (GET, POST, DELETE, PUT) 기반 API 지원
- 분산 모드 커넥트 실행 방법
- connect-distributed.properties 파일(분산 모드 설정 파일) 설정
- 이 파일은 분산 모드 커넥트를 묶어서 운영하기 위한 설정 정보를 담고 있음
- 카프카 설치 디렉토리의 config 폴더에 위치
- 설정 파일은 아래 코드 블럭에서 다룬다
- REST API를 통한 관리
- 분산 모드 커넥트를 실행할 때는 커넥트 설정 파일만 있으면 OK
- 커넥터는 커넥트가 실행된 이후 REST API를 통해 실행 / 중단 / 변경 가능하기 때문
- connect-distributed.properties 파일(분산 모드 설정 파일) 설정
connect-distributed.properties
# 커넥트와 연동할 카프카 클러스터의 호스트와 포트 작성
bootstrap.servers=localhost:9092
# 다수의 커넥트 프로세스들을 묶을 그룹 이름을 지정
# 동일한 group.id로 지정된 커넥트들은 같은 그룹으로 인식되며, 같은 그룹으로 지정된 커넥트들에서 커넥터가 실행되면 커넥터들에 분산되어 실행됨
group.id=connect-cluster
# 데이터를 카프카에 저장할 때 혹은 카프카에서 데이터를 가져올 때 변환하는 데에 사용
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 분산 모드 커넥트는 '카프카 내부 토픽(internal topic)'에 오프셋 정보를 저장
# 오프셋 정보는 소스 커넥터 또는 싱크 커넥터가 데이터 처리 시점을 저장하기 위해 사용
# 해당 정보는 데이터를 처리하는 데에 있어 중요한 역할을 하므로, 실제 운영 시에는 복제 개수를 3보다 큰 값으로 설정하는 것이 좋음
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#offset.storage.partitions=25
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
#status.storage.partitions=5
# 태스크가 처리 완료한 오프셋을 커밋하는 주기를 설정
offset.flush.interval.ms=10000
# 오픈소스로 다운 받았거나 직접 개발한 커넥터의 jar 파일이 위치하는 디렉토리 주소 입력
plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
다음의 커맨드를 통해 분산 모드 커넥트를 실행할 수 있다
$ bin./connect-distributed.sh config/connect-distributed.properties소스 커넥터와 싱크 커넥터를 직접 구현하는 방법에 대해서는 생략하도록 하겠다
카프카 미러메이커2(Kafka MirroMaker2)
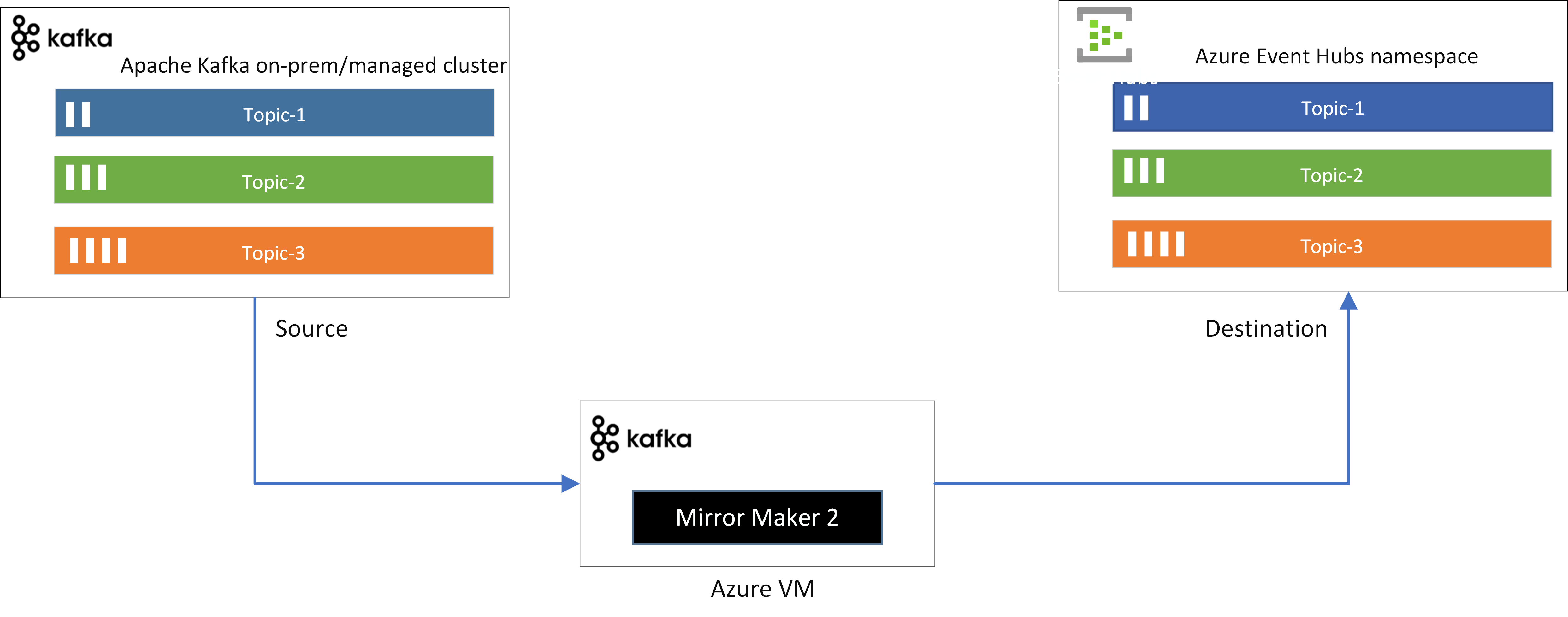
- 카프카 미러메이커2(MirrorMaker2): 서로 다른 두 개의 카프카 클러스터 간의 토픽을 복제하는 애플리케이션
- 카프카 미러메이커2를 사용하는 이유
- 토픽의 모든 것을 복제할 필요성이 있기 때문
- 프로듀서와 컨슈머를 사용해서 2개의 서로 다른 클러스터에 토픽의 데이터를 완전히 동일하게 옮기는 것은 어려움
- 이에 대한 모든 기능을 제공하는 것이 '카프카 미러메이커2'이다
- 특징
- 양방향 토픽 복제 지원
- 토픽의 데이터를 복제할 뿐만 아니라 토픽 설정까지도 복제
- => 파티션의 변화, 토픽 설정값의 변화도 동기화 가능
- 커넥터로 사용할 수 있도록 설계됨
- => 분산 모드 커넥트를 운영하고 있다면 커넥트에서 미러메이커2 커넥터를 실행하여 토픽 복제 가능
- 정확히 한번 전달(exactly once delivery)를 보장하여 데이터 유실 및 중복을 막음
단방향 토픽 복제
- 미러메이커2를 사용하기 위해서는 connect-mirror-maker.properties 파일 수정 필요
- 카프카 설치 디렉토리의 config 폴더에 위치
- 카프카 클러스터들에 대한 정보와 토픽 정보, 토픽을 복제하면서 사용할 내부 토픽에 대한 정보를 포함한다
# 카프카 클러스터 A와 카프카 클러스터 B가 있을 경우를 가정
# 클러스터 A에 존재하는 test라는 이름의 토픽을 클러스터 B로 복제할 경우 다음과 같이 작성
# 복제할 클러스터의 닉네임 작성 (여기서는 A, B라고 정함)
# 이 클러스터 닉네임은 아래 옵션에서 다시 사용됨
# 이 클러스터 이름은 토픽이 복제될 때 토픽의 접두사(prefix)로 붙게 됨
clusters = A, B
# 사용할 클러스터의 접속 정보를 작성
A.bootstrap.servers = a-kafka:9092
B.bootstrap.servers = b-kafka:9092
# 클러스터 A에서 클러스터 B로 복제를 진행할 것인지, 그리고 어떤 토픽을 복제할 것인지를 명시
# 여기서는 클러스터 A에서 클러스터 B로 test 토픽을 복제하므로 enabled=true로 설정하고 topics=test로 설정
A->B.enabled = true
A->B.topics = test
# 미러메이커2는 양방향 토픽 복제가 가능
# 여기서는 클러스터 A에서 클러스터 B로 복제를 진행하므로 enabled=false로 설정
B->A.enabled = false
B->A.topics = .*
# 복제되어 신규 생성된 토픽의 복제 개수 설정
replication.factor=1
############################# Internal Topic Settings #############################
# 토픽 복제에 필요한 데이터를 저장하는 내부 토픽의 복제 개수 설정
checkpoints.topic.replication.factor=1
heartbeats.topic.replication.factor=1
offset-syncs.topic.replication.factor=1
offset.storage.replication.factor=1
status.storage.replication.factor=1
config.storage.replication.factor=1
이후 다음의 커맨드로 설정 파일과 함께 실행
$ bin/connect-mirror-maker.sh config/connect-mirror-maker.properties- 이제 클러스터 A의 test 토픽에 데이터를 저장하면, 이는 클러스터 B의 'A.test' 토픽에 저장된다.
- A.test에서 A는 설정파일에서 설정한 클러스터 A의 닉네임이다
- 클러스터 A의 파티션 수를 변경해도 동기화되어 클러스터 B에도 적용된다
지리적 복제(Geo-Replication)
- 미러메키어2를 사용함으로써 카프카 클러스터 단위의 활용도를 높일 수 있다
- 미러메이커가 제공하는 단방향/양방향 복제 가능, ACL 복제, 새 토픽 자동 감지 등의 기능은 클러스터가 2개 이상일 때 더욱 빛난다
- 액티브-스탠바이(Active-stanby) 클러스터 운영
- 서비스 애플리케이션과 통신하는 카프카 클러스터 외에 재해 복구를 위해 임시 카프카 클러스터를 하나 더 구성하는 방식
- 액티브 클러스터: 서비스 애플리케이션과 직접 통신하는 카프카 클러스터
- 스탠바이 클러스터: 재해 복구를 위한 나머지 1개 카프카 클러스터
- 액티브 클러스터의 모든 토픽응ㄹ 스탠바이 클러스터에 복제하여, 액티브 클러스터의 예상치 못한 장애에 대응 가능
- ex) 한국에 위치한 데이터 센터가 재해로 일시 중단되더라도 미러메이커2로 지속적으로 데이터를 일본에 위치한 스탠바이 크러스터로 시스템 대체 작동(failover)하여 서비스의 완전 중단을 막을 수 있음
- 단, 액티브->스탠바이 클러스터로의 데이터 복제 시 복제가 지연되는 현상인 '복제 랙(replication lag)'이 발생 가능
- 때문에 스탠바이 클러스터로 전환되더라도 데이터가 중복 또는 유실 처리될 수 있음
- 이에 대한 대응 방안을 사전에 정하고 운영하는 것이 중요
- 또한, 실제로 장애가 발생했을 경우 스탠바이 클러스터로 자연스럽게 넘어가는지는 상황이 발생하기 전까지 알 수가 없음
- 장애 복구 훈련을 계획하고 수행하는 것이 매우 중요
- 액티브-액티브(Active-active) 클러스터 운영
- 글로벌 서비스 운영 시, 서비스 애플리케이션의 통신 지연을 최소화하기 위해 2개 이상의 클러스터를 두고 서로 데이터를 미러링하면서 사용하는 방식
- ex) 물리적으로 아주 멀리 떨어진 곳에 있는 두 명의 유저의 데이터를 저장하고 사용하는 방법으로 각 지역마다 클러스터를 두고 필요한 데이터만 복제하여 사용하는 방법을 채택할 수 있음 -> 데이터 지연 최소화
- 허브 앤 스포크(Hub and spoke) 클러스터 운영
- 각 팀에서 소규모 카프카 클러스터를 사용하고 있을 때, 각 팀의 카프카 클러스터의 데이터를 한 개의 카프카 클러스터에 모아 데이터 레이크로 사용하는 방식
- '허브'는 중앙에 있는 한 개의 점, '스포크'는 중앙의 점과 다른 점들을 연결한 선
- 허브가 중앙에 위치한 데이터 레이크 용도의 카프카 클러스터를 의미
- 미러메이커2를 사용하여 각 팀에서 사용하는 카프카 클러스터에 존재하는 데이터를 수집하고, 데이터 레이크용 카프카 클러스터(허브)에서 가공 및 분석하여 가치 있는 데이터를 추출할 수 있다
- 필요에 따라 양방향 토픽 복제를 통해 데이터 레이크용 카프카 클러스터에 저장된 다른 팀의 데이터를 조합하여 사용하는 방법도 있다
'Data Infra' 카테고리의 다른 글
| [Apache Kafka] 카프카 프로듀서 상세 개념 (2) | 2024.12.11 |
|---|---|
| [Apache Kafka] 토픽과 파티션 상세 개념 (2) | 2024.12.11 |
| [Apache Kafka] 카프카 기본 개념 (3) | 2024.12.10 |
| [Apache Kafka] 카프카 설치와 커맨드 라인 툴 (3) | 2024.12.04 |
| [Apache Kafka] 카프카의 탄생과 미래 (1) | 2024.12.03 |