
728x90
반응형
적정 파티션 개수
- 토픽의 파티션 개수는 카프카의 성능과 관련이 있음
- => 적절한 파티션 개수를 설정하고 운영하는 것이 매우 중요
- 토픽 생성 시 파티션 개수 고려사항
- 데이터 처리량
- 메시지 키 사용 여부
- 브로커, 컨슈머 영향도
데이터 처리량
- 파티션 = 카프카 병령처리의 핵심
- 파티션 개수가 많아질수록 1:1 매핑되는 컨슈머 개수 증가
- => 파티션 개수 정할 때는 토픽에 필요한 데이터 처리량을 측정하는 것이 중요
- 데이터 처리 속도 향상시키는 방법 2가지
- 컨슈머 자체의 처리량을 늘리기
- 컨슈머가 실행되는 서버의 사양을 스케일 업
- GC 튜닝
- etc..
- but, 컨슈머 특성상 다른 시스템들(S3, 하둡, 오라클 등)과 연동되기 때문에 일정 수준 이상 처리량을 올리는 것은 매우 어려움..
- 컨슈머를 추가해서 병렬처리량 늘리기
- 가장 확실한 방법
프로듀서 전송 데이터양 < 컨슈머 데이터 처리량 x 파티션 개수유지하기- 파티션 개수만큼 컨슈머 스레드를 운영하면 해당 토픽의 병렬처리 극대화 가능
프로듀서 전송 데이터양 > 컨슈머 데이터 처리량 x 파티션 개수일 경우 => 컨슈머 랙 발생 => 데이터 처리 지연
- 컨슈머 자체의 처리량을 늘리기
- 컨슈머 데이터 처리량 구하는 법
- 상용에서 운영 중인 카프카에서 더미 데이터로 테스트 해보기
- 로컬 또는 테스트 환경에서 진행한 데이터 처리량과 상용 환경에서 진행한 데이터 처리량은 차이가 날 확률이 높으므로, 반드시 상용 환경 테스트 진행하기
- 프로듀서 전송 데이터양 구하는 법
- 프로듀서가 보내는 데이터양을 하루, 시간, 분 단위로 쪼개서 예측
- 데이터 지연 절대 발생하면 안된다면, 데이터의 최대치를 데이터 생성량으로 잡고 계산
- 파티션 개수를 늘릴 수록 컨슈머, 브로커에 부담 => 무조건 개수를 늘린다고 좋은 것이 아님
- 데이터를 처리함에 있어서 지연 발생에 따른 서비스 영향도를 같이 고려하여 파티션 개수를 구하는 것이 중요
메시지 키 사용 여부
- 정확히 말하자면, 메시지 키를 사용함과 동시에 데이터 처리 순서를 지켜야 하는 경우를 고려
- 메시지 키 사용 여부는 데이터 처리 순서와 밀접한 연관
- 프로듀서가 기본 파티셔너를 사용한다면, 동일한 메시지 키에 대해서는 동일한 파티션에 매칭 -> 메시지 키 순서 보장
- 그러나, 파티션 개수가 달라지면 특정 메시지 키의 순서를 더는 보장 X
- 파티션 개수가 변해야 하는 경우, 순서가 중요하다면 커스텀 파티셔너를 개발하고 적용해야 함
- 이는 수고스러운 작업이므로 처음부터 파티션 개수를 프로듀서가 전송하는 데이터양보다 더 넉넉하게 잡고 생성할 것을 권장
- 데이터 처리 순서를 고려하지 않아도 된다면, 넉넉하게 잡을 필요 없이 데이터 양에 따라 파티션을 늘리는 전략 취하기
브로커, 컨슈머 영향도
- 파티션은 각 브로커의 파일 시스템을 사용하기 때문에 파티션이 늘어나는 만큼 브로커에서 접근하는 파일 개수가 증가
- but, OS에서는 프로세스 당 열 수 있는 파일 최대 개수가 제한 => 각 브로커당 파티션 개수 모니터링 필수
- 데이터양이 많아져서 파티션 개수를 늘려야 하는 상황이라면, 브로커당 파티션 개수를 확인하고 진행
- 만약 파티션 개수가 너무 많다면 카프카 브로커 개수를 늘리는 방안도 고려 필요
토픽 관리 정책(cleanup.policy)
- 토픽의 데이터는 시간 또는 용량에 따라 삭제 규칙 적용 가능
- 또는 삭제를 원치 않으면 삭제하지 않도록 설정 가능
- 그러나 데이터를 오랫동안 삭제하지 않으면 저장소 사용량이 지속적으로 증가 => 비용 증가
- => 다시 사용하지 않을 데이터의 경우 cleanup.policy 옵션을 사용해 데이터를 삭제하자
- **clenaup.policy의 2가지 삭제 정책
- 토픽 삭제 정책: 데이터 완전 삭제하는 것
- 토픽 압축 정책: 동일 메시지 키의 가장 오래된 데이터를 삭제하는 것
토픽 삭제 정책(delete policy)
일반적으로 대부분의 토픽의 cleanup.policy를 delete로 설정
토픽 데이터 삭제는 '세그먼트 단위'로 삭제 진행
- 세그먼트: 토픽의 데이터를 저장하는 명시적인 파일 시스템 단위
- 세그먼트는 파티션마다 별개로 생성되며, 세그먼트의 파일 이름은 오프셋 중 가장 작은 값이 됨
- 세그먼트는 여러 조각으로 나뉘는데, segment.bytes 옵션으로 1개의 세그먼트 크기 설정 가능
- segment.bytes 옵션값보다 크기가 커지면, 기존 적재 중이던 세그먼트 파일을 닫고 새로운 세그먼트 파일에 적재 시작
- 액티브 세그먼트: 데이터를 저장하기 위해 사용 중인 세그먼트
삭제 정책 실행 시점은 시간 또는 용량이 기준 (각 기준을 넘으면 삭졔)
- retention.ms: 토픽의 데이터를 유지하는 기간을 밀리초로 설정 가능
- retention.bytes: 토픽의 최대 데이터 크기를 설정 가능
삭제된 데이터는 복구할 수 없다
토픽 압축 정책(compact policy)
- 여기서 압축이란, 메시지 키별로 해당 메시지 키의 레코드 중 오래된 데이터를 삭제하는 정책을 의미
- 오래된 데이터를 삭제하기 때문에 삭제 정책과 다르게 1개 파티션에서 오프셋의 증가가 일정하지 않을 수 있음
- ex) 데이터가 압축되어 3번 오프셋의 레코드 다음에 5번 오프셋의 레코드가 조회될 수 있음
- 토픽 압축 정책은 카프카 스트림즈의 KTable과 같이 메시지 키를 기반으로 데이터를 처리할 경우 유용
- 압축 정책은 액티브 세그먼트를 제외한 나머지 세그먼트들에 한해서만 데이터를 처리함
- 데이터 압축 시작 시점은 min.cleanable.dirty.ratio 옵션값을 따름
- min.cleanable.dirty.ratio: 액티브 세그먼트를 제외한 세그먼트에 남아있는 데이터의 테일(tail) 영역의 레코드 개수와 헤드(head) 영역의 레코드 비율을 뜻함
- 테일 영역: 브로커의 압축 정책에 의해 압축이 완료된 레코드
- 이 영역의 레코드들을 '클린 로그'라고 부름
- 압축 완료되었으므로 테일 영역에는 중복된 메시지 키 없음
- 헤드 영역: 압축이 되지 않은 레코드
- 이 영역의 레코드들을 '더티 로그'라고 부름
- 압축 되지 않았기에 중복된 메시지 키를 가진 레코드들이 있을 수 있음
더티 비율(dirty ratio) = 더티 레코드 개수 / (클린 레코드 개수 + 더티 레코드 개수)- min.cleanable.ratio 값을 0.5로 설정할 경우, 더티 비율이 0.5가 넘어가면 압축 수행
- 크게 설정할 수록 압축 효과는 좋지만, 해당 비율이 될 때까지 용량을 차지하게 되어 용량 효율은 좋지 않음
- 작게 설정할 수록 압축이 더 자주 일어나서 용량 효율이 좋고 최신 데이터만 유지할 수 있지만, 압축이 자주 발생하는만큼 브로커에 부담이 될 수 있음
ISR(In-Sync-Replicas)
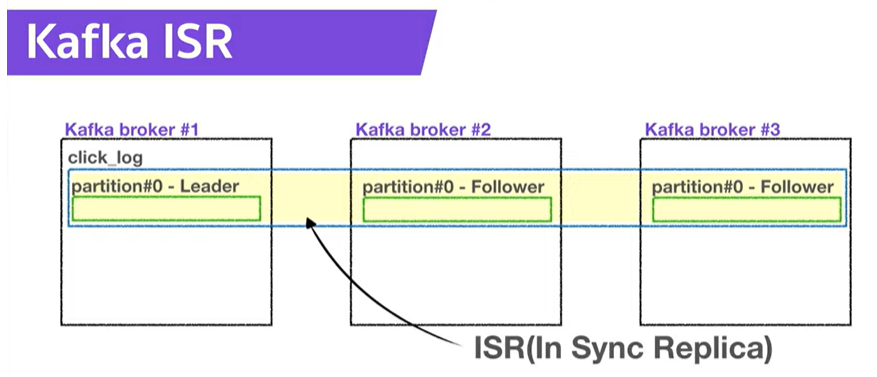
ISR: 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태
동기화(싱크)가 되었다는 것은 리더 파티션의 모든 데이터가 팔로워 파티션에 복제되었음을 의미
- 동기화된 상태에서는 리더 또는 팔로워 파티션이 위치하는 브로커에 장애가 발생하더라도 데이터를 안전하게 사용 가능
팔로워 파티션이 리더 파티션으로부터 데이터를 복제하는 데에는 시간이 걸림..
- => 리더와 팔로워 간의 오프셋 차이가 발생할 수 있음
이러한 차이를 모니터링 하기 위해 리더 파티션은 replica.lag.time.mxa.ms 값만큼의 주기를 가지고 팔로워 파티션이 데이터를 복제하는지 확인
- 팔로워 파티션이 replica.lag.time.mxa.ms 값보다 더 긴 시간 동안 데이터를 가져가지 않는다면, 해당 팔로워 파티션에 문제가 생긴 것으로 판단하고 ISR 그룹에서 제외
ISR로 묶인 리더 파티션과 팔로워 파티션은 파티션에 존재하는 데이터가 모두 동일하기 때문에 팔로워 파티션은 리더 파티션으로 새로 선출될 자격을 갖춤
- 반면, ISR로 묶이지 않은 팔로워 파티션은 리더로 선출될 수 없음
일부 데이터 유실이 발생하더라도 서비스 중단 없이 지속적으로 토픽을 사용하고 싶다면, ISR이 아닌 팔로워 파티션을 리더로 선출하도록 설정 가능
- unclean.leader.election.enable 옵션을 false 또는 true로 설정
- false: ISR이 아닌 팔로워 파티션을 리더로 선출하지 않는다 -> 리더 파티션이 존재하는 브로커가 다시 시작될 때까지 대기
- 장점: 데이터 유실은 발생 X
- 단점: 장애 발생한 브로커가 다시 실해오딜 때까지 해당 토픽은 사용 불가능
- true: ISR이 아닌 팔로워 파티션, 즉 동기화되지 않은 팔로워 파티션도 리더로 선출될 수 있음
- 장점: 서비스 중단 발생 X
- 단점: 데이터 유실 가능성 존재
- false: ISR이 아닌 팔로워 파티션을 리더로 선출하지 않는다 -> 리더 파티션이 존재하는 브로커가 다시 시작될 때까지 대기
- unclean.leader.election.enable 옵션을 false 또는 true로 설정
unclean.leader.election.enable 옵션은 토픽별로 설정 가능하며, 토픽 생성 시 설정하는 방법은 다음과 같음
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --config unclean.leader.election.enable=false728x90
반응형
'Data Infra' 카테고리의 다른 글
| [Apache Kafka] 카프카 컨슈머 상세 개념 (2) | 2024.12.11 |
|---|---|
| [Apache Kafka] 카프카 프로듀서 상세 개념 (2) | 2024.12.11 |
| [Apache Kafka] 카프카 스트림즈, 카프카 커넥트, 카프카 미러메이커2 (2) | 2024.12.10 |
| [Apache Kafka] 카프카 기본 개념 (3) | 2024.12.10 |
| [Apache Kafka] 카프카 설치와 커맨드 라인 툴 (3) | 2024.12.04 |