
728x90
반응형
이번에는 컨슈머의 고급 활용법과 옵션별 동작 방식에 대해 자세히 알아보자
멀티 스레드 컨슈머
- 데이터를 병렬처리하기 위해서 파티션 개수와 컨슈머 개수를 동일하게 맞추는 것이 가장 좋음
- 파티션 개수가 n개라면 동일 컨슈머 그룹으로 묶인 컨슈머 스레드를 최대 n개 운영 가능
- => n개의 스레드를 가진 1개의 프로세스를 운영 or 1개의 스레드를 가진 프로세스를 n개 운영
- 멀티 스레드를 지원하지 않는 언어 또는 환경 -> 프로세스 여러 개
- 멀티 스레드 지원하는 경우 -> 컨슈머 스레드를 여러 개
- 자바는 멀티 스레드 지원
- 멀티 스레드로 컨슈머를 안전하게 운영하기 위한 고려사항
- 하나의 컨슈머 스레드에서 예외적 상황(ex. OutofMemoryException)이 발생할 경우 프로세스 자체가 종료되어 다른 스레드에 영향을 줄 수 있음
- 컨슈머 스레드의 비정상 종료 시 데이터 처리에서 중복 또는 유실 발생 가능
- 가 컨슈머 스레드 간 영향이 없더록 스레드 세이프 로직, 변수를 적용해야 함
- 컨슈머를 멀티 스레드로 활용하는 방식 2가지
- 멀티 워커 스레드 전략: 컨슈머 스레드는 1개, 데이터 처리를 담당하는 워커 스레드(worker thread)를 여러 개 실행
- 컨슈머 멀티 스레드 전략: 컨슈머 인스턴스에서 poll() 메서드를 호출하는 스레드를 여러 개 실행
멀티 워커 스레드 전략
public class MultiWorkerThreadConsumer {
private final static Logger logger = LoggerFactory.getLogger(MultiWorkerThreadConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// ExecutorService는 다양한 스레드 풀을 제공하는데, 여기서는 레코드 출력 이후 스레드를 종료하도록 newCachedThreadPool 사용
// newCachedThreadPool: 필요한만큼 스레드 풀을 늘려서 스레드를 실행하는 방식으로, 짧은 시간의 생명 주기를 가진 스레드에서 유용
// 레코드들을 처리하는 스레드를 레코드마다 개별 실행한다
ExecutorService es = Executors.newCachedThreadPool();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, String> record : records) {
logger.info("{}", record);
ConsumerWorker worker = new ConsumerWorker(record.value());
logger.info("워커 스레드 생성 및 실행");
es.execute(worker); // execute() 메서드를 통해 스레드 실행
}
}
}
// 데이터를 처리하는 사용자 지정 스레드 생성
public static class ConsumerWorker implements Runnable {
private final static Logger logger = LoggerFactory.getLogger(ConsumerWorker.class);
private String recordValue;
public ConsumerWorker(String recordValue) {
this.recordValue = recordValue;
}
// 데이터를 처리하는 로직 넣기
@Override
public void run() {
logger.info("thread:{}\trecord:{}", Thread.currentThread().getName(), recordValue);
}
}
}- 1개의 컨슈머 스레드로 받은 데이터들을 여러 개의 워커 스레드로 처리하는 것
- 멀티 스레드를 사용하면 한번 poll()을 통해 받은 데이터를 병렬 처리함으로써 속도의 이점을 확실히 얻을 수 있음
- 몇 가지 주의사항
- 스레드를 사용함으로써 데이터 처리가 끝나지 않았음에도 불구하고 커밋 => 리밸런싱, 컨슈머 장애 시 데이터 유실 발생 가능
- 오토 커밋일 경우 데이터 처리가 스레드에서 진행 중임에도 불구하고, 다음 poll() 메서드 호출 시 커밋을 할 수 있기 때문에 발생하는 현상
- 레코드 처리의 역전 현상
- for 반복 구문을 통해 스레드의 생성은 순서대로 진행
- but, 스레드의 처리 시간은 각기 다를 수 있음.. => 레코드의 순서가 뒤바뀌는 현상 발생
- 스레드를 사용함으로써 데이터 처리가 끝나지 않았음에도 불구하고 커밋 => 리밸런싱, 컨슈머 장애 시 데이터 유실 발생 가능
- 이러한 특징들로 인해, 레코드 처리에 있어 중복이 발생하거나 데이터의 역전현상이 발생해도 되며, 매우 빠른 처리 속도가 필요한 데이터 처리에 적합함
- ex) 서버 리소스(CPU, 메모리 등) 모니터링 파이프라인, IoT 서비스의 센서 데이터 수집 파이프라인
- 데이터 처리 순서가 민감한 경우에는 스레드를 사용하여 데이터를 처리할 때 순서가 역전되지 않도록 주의해야 함
멀티 스레드 전략
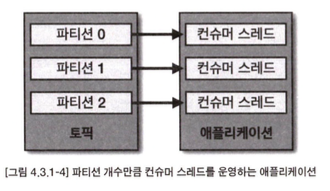
- 1개의 애플리케이션에 구독하고자 하는 토픽의 파티션 개수만큼 컨슈머 스레드 개수를 늘려서 운영하는 것
- 각 스레드에 각 파티션이 할당되며, 파티션의 레코드들을 병렬 처리 가능
- 주의해야 할 점은 구독하고자 하는 토픽의 파티션 개수만큼만 컨슈머 스레드를 운영해야 함
- "컨슈머 스레드 > 파티션 수" => 파티션에 할당되지 못한 컨슈머 스레드가 생겨 낭비됨
public class MultiConsumerThread {
private final static Logger logger = LoggerFactory.getLogger(MultiConsumerThread.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
private final static int CONSUMER_COUNT = 3;
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
ExecutorService es = Executors.newCachedThreadPool();
for (int i = 0; i < CONSUMER_COUNT; i++) {
ConsumerWorker worker = new ConsumerWorker(configs, TOPIC_NAME, i);
es.execute(worker);
}
}
// 데이터를 처리하는 사용자 지정 스레드 생성
public static class ConsumerWorker implements Runnable {
private final static Logger logger = LoggerFactory.getLogger(ConsumerWorker.class);
private Properties configs;
private String topic; // 구독할 토픽 이름
private String threadName; // 스레드를 구별하기 위한 스레드명
// KafkaConsumer 클래스는 스레드 세이프하지 않기 때문에, 스레드별로 KafkaConsumer 인스턴스를 별개로 만들어서 운영한다.
// 하나의 KafkaConsumer 인스턴스를 여러 스레드에서 실행하면 ConcurrentModificationException 예외가 발생한다
private KafkaConsumer<String, String> consumer;
public ConsumerWorker(Properties configs, String topic, int number) {
this.configs = configs;
this.topic = topic;
this.threadName = "consumer-thread-" + number;
}
@Override
public void run() {
consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, String> record : records) {
logger.info("thread: {}, record: {}", threadName, record);
}
}
}
}
}컨슈머 랙
- 컨슈머 랙(LAG): 토픽의 최신 오프셋(LOG-END-OFFSET)과 컨슈머 오프셋(CURRENT-OFFSET) 간의 차이
- 컨슈머 랙은 컨슈머가 정상 동작하는지 여부를 확인할 수 있기 때문에 컨슈머 애플리케이션을 운영한다면 필수적으로 모니터링해야 함
- 컨슈머 랙은 컨슈머 그룹과 토픽, 파티션별로 생성됨
- ex) 1개의 토픽에 3개의 파티션이 있고, 1개의 컨슈머 그룹이 토픽을 구독하여 데이터를 가져간다면 => 컨슈머 랙은 총 3개

- 프로듀서 전송량 > 컨슈머 처리량 => 컨슈머 랙 증가
- 프로듀서 전송량 < 컨슈머 처리량 => 컨슈머 랙 감소
컨슈머 랙을 모니터링함으로써 컨슈머의 장애를 확인할 수 있고, 파티션 개수를 정하는 데에 참고할 수 있다

- 처리량 이슈: 컨슈머는 프로듀서가 전송하는 데이터양이 늘더라도, 최대 처리량은 한정.. => 프로듀서 전송량이 증가하면 컨슈머 랙 발생
- => 지연을 줄이기 위해 일시적으로 파티션 개수 & 컨슈머 개수를 늘려 병렬처리량을 늘리는 방법 사용 가능

- 컨슈머 이슈: 프로듀서 전송량이 일정하더라도, 컨슈머의 장애로 인해 컨슈머 랙이 증가할 수 있음
- 프로듀서가 보내는 데이터량의 변화가 없는데, 특정 파티션의 컨슈머 랙이 증가하는 상황이라면? => 해당 컨슈머에 이슈가 있음
카프카 명령어를 사용한 컨슈머 랙 조회
kafka-consumer-groups.sh커맨드를 사용해 특정 컨슈머 그룹의 상태를 확인 가능- but, 명령어를 사용하는 방식은 일회성에 그치고, 지표를 지속적으로 기록, 모니터링하기에는 부족
= => 주로 테스트용 카프카에서 사용
컨슈머 metrics() 메서드를 사용한 컨슈머 랙 조회
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
// 컨슈머에게 토픽을 할당한다. Collection 타입을 통해 1개 이상의 토픽을 전달할 수 있다.
consumer.subscribe(Arrays.asList(TOPIC_NAME));
Map<MetricName, ? extends Metric> metrics = consumer.metrics();
for (Map.Entry<MetricName, ? extends Metric> entry : metrics.entrySet()) {
if ("records-lag-max".equals(entry.getKey().name()) |
"records-lag".equals(entry.getKey().name()) |
"records-lag-avg".equals(entry.getKey().name())
) {
Metric metric = entry.getValue();
logger.info("{}:{}", entry.getKey().name(), metric.metricValue());
}
}- 컨슈머의 metrics() 메서드를 통해 컨슈머 랙 지표를 확인 가능
- 컨슈머 랙 관련 모니터링 지표는 3가지
- records-lag
- records-lag-max
- records-lag-avg
- but, 다음과 같은 3가지 문제점 존재
- 컨슈머가 실행하므로 컨슈머에 장애가 발생하는 경우 더 이상 랙을 모니터링 불가
- 모든 컨슈머 애플리케이션에 모니터링 코드 중복
- 카프카 서드 파티 애플리케이션의 컨슈머 랙 모니터링 불가
외부 모니터링 툴을 사용한 커슈머 랙 조회
- 컨슈머 랙을 모니터링하는 가장 최선의 방법
- ex) 데이터독(Datadog), 컨플루언트 컨트롤 센터(Confluent Control Center)와 같은 카프카 클러스터 종합 모니터링 툴 사용
- 외부 모니터링 툴 사용 시 장점
- 카프카 클러스터에 연결된 모든 컨슈머, 토픽들의 랙 정보를 한번에 모니터링 가능
- 모니터링 툴들은 클러스터와 연동되어 컨슈머의 데이터 처리와는 별개로 지표를 수집함 => 데이터를 활용하는 프로듀서나 컨슈머의 동작에 영향 X
카프카 버로우(Burrow)
- 링크드인에서 개발하여 오픈소스로 공개한 컨슈머 랙 체크 툴
- REST API를 통해 컨슈머 그룹별로 컨슈머 랙 확인 가능

- 다수의 카프카 클러스터를 동시에 연결하여 랙을 확인
- 한 번의 설정으로 다수의 카프카 클러스터 컨슈머 랙 확인 가능
- 단, 모니터링을 위해 컨슈머 랙 지표 수집, 적재, 알람 설정 등을 하고 싶다면 별도의 저장소(ex. 엘라스틱 서치)와 대시보드(ex. 그라파나, 키바나)를 구축해야 함
- 버로우는 컨슈머와 파티션의 상태를 단순히 컨슈머 랙의 임계치로 나타내지 않았음
- 프로듀서가 데이터를 많이 보내면 일시적으로 임계치가 넘어갈 수 있음 => 단순 임계치만으로 알람 받는 것은 무의미
- => 버로우는 임계치가 아닌 슬라이딩 윈도로 계산해 문제가 생긴 파티션과 컨슈머의 상태를 표현한다.
- = 컨슈머 랙 평가(evaluation)
일반적인인 경우(파티션 OK, 컨슈머 OK)

- 프로듀서가 지속적으로 데이터를 추가 & 컨슈머가 데이터를 처리 => 때때로 랙이 증가하지만 다시 0으로 줄어드는 추이
- => 컨슈머 정상 동작
- => 파티션 OK, 컨슈머 OK
컨슈머 처리량 이슈(파티션 OK, 컨슈머 WARNING)

- 프로듀서가 추가하는 최신 오프셋을 컨슈머의 오프셋이 따라가지 못하는 추이
- 컨슈머의 처리량이 프로듀서의 전송량에 비해 적음 => 거리가 계속 벌어지며 컨슈머 랙 지속적으로 증가
- => 파티션 OK, 컨슈머 WARNING
- 파티션 개수와 컨슈머 개수를 늘리면 해결 가능
컨슈머 이슈 발생(파티션 STALLED, 컨슈머 ERROR)

- 최신 오프셋은 계속 증가하지만 컨슈머 오프셋이 멈추고 랙이 증가하는 추이
- 컨슈머가 데이터를 더는 가져가지 않음 => 비정상 동작
- => 파티션 STALLED, 컨슈머 ERROR
- 이메일, SMS, 슬랙 등의 알람 받고 즉각 조치 필요
컨슈머 랙 모니터링 아키텍처 예시
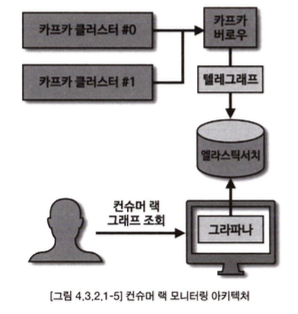
- 이미 지나간 컨슈머 랙을 개별적으로 모니터링 하기 위해서 별개의 저장소와 대시보드를 사용하는 것이 효과적
- 준비물
- 버로우: REST API를 통해 컨슈머 랙 조회 가능
- 텔래그래프: 데이터 수집 및 전달에 특화된 툴. 버로우를 조회하여 데이터를 엘라스틱 서치에 전달
- 엘라스틱 서치: 컨슈머 랙 정보를 담는 저장소
- 그라파나: 엘라스틱 서치의 정보를 시각화하고 특정 족너에 따라 슬랙 알람을 보낼 수 있는 웹 대시보드 툴
컨슈머 배포 프로세스
- 카프카 컨슈머 애플리케이션 운영 시 로직 변경으로 인한 배포를 하는 방법은 크게 2가지
- 중단 배포
- 무중단 배포
- 짧은 시간 동안 중단이 되어 지연이 발생하더라도 서비스 운영에 이슈가 없다 => 중단 배포 사용
- 중단이 발생하면 서비스에 영향이 클 경우 => 무중단 배포 사용
중단 배포
- 컨슈머 애플리케이션을 완전히 종료한 이후에 개선된 코드를 가진 애플리케이션을 배포하는 방식
- 한정된 서버 자원을 운영하는 기업에 적합
- 기존 애플리케이션을 완전히 종료한 이후 신규 애플리케이션을 배포, 실행하여 버전을 올리는 방식
- 기존 컨슈머 애플리케이션 종료 -> 토픽 데이터를 가져갈 수 없음.. -> 컨슈머 랙 증가 & 지연 발생
- 배포에 이슈가 생겨 배포와 실행이 늦어지면 해당 파이프라인을 운영하는 서비스는 계속해서 중단됨..
- 장점
- 새로운 로직이 적용된 신규 애플리케이션의 실행 전후를 명확하게 '특정 오프셋 지점'으로 나눌 수 있음
- => 롤백할 때 유용
무중단 배포
- 배포를 위해 신규 서버를 발급해야함 -> 인스턴스의 발급과 반환이 다소 유연한 가상 서버를 사용하는 경우에 유용
- 무중단 배포의 3가지 방법
- 블루/그린 배포
- 이전 버전 애플리케이션과 신규 버전 애플리케이션을 동시에 띄워놓고 트래픽을 전환하는 방법
- 실행할 애플리케이션이 '파티션 개수 = 컨슈머 개수'일 경우 유용
- 파티션 개수와 컨슈머 개수가 다르게 운영되고 있다면, 일부 파티션은 기존 애플리케이션에 할당되고 일부 파티션은 신규 애플리케이션에 할당되어 섞일 수 있음
- 신규 버전 애플리케이션들이 준비되면, 기존 애플리케이션을 모두 중단하면 됨
- 기존 애플리케이션 중단 시 리밸런싱이 발생하면서 파티션은 모두 신규 컨슈머와 연동됨
- 리밸런스가 한 번만 발생 => 많은 수의 파티션을 운영하는 경우에도 짧으 ㄴ리밸런스 시간으로 배포 수행 가능
- 롤링 배포
- 롤링 배포는 블루/그린 배포의 인스턴스 할당과 반환으로 인한 리소스 낭비를 줄이면서 무중단 배포 가능
- 파티션 개수가 인스턴스 개수와 같거나 많아야 함
- ex) 파티션 2개, 인스턴스 2개의 경우
- 2개 중 1개의 인스턴스를 신규 버전으로 먼저 실행 & 모니터링
- 이후 나머지 1개의 인스턴스를 신규 버전으로 배포하여 롤링 업그레이드
- 이 경우 리밸런스가 '인스턴스 수만큼' 발생
- 파티션 개수가 많을수록 리밸런스 시간 증가 => 파티션 개수가 많지 않은 경우 효과적
- 카나리 배포
- 많은 데이터 중 일부분을 신규 버전의 애플리케이션으로 먼저 배포함으로써 이슈가 없는지 사전에 탐지 (배포 사전 테스트)
- ex) 100개 파티션으로 운영하는 토픽이 있다면, 1개 파티션에 컨슈머를 따로 배정하여 일부 데이터에 대해 신규 버전의 애플리케이션이 우선적으로 처리하는 방식으로 테스트 가능
- 카나리 배포로 사전 테스트가 완료되면 나머지 99개 파티션에 할당된 컨슈머는 롤링 또는 블루/그린 배포를 수행하여 무중단 배포 수행
- 블루/그린 배포
728x90
반응형
'Data Infra' 카테고리의 다른 글
| [Apache Kafka] 카프카 프로듀서 상세 개념 (2) | 2024.12.11 |
|---|---|
| [Apache Kafka] 토픽과 파티션 상세 개념 (2) | 2024.12.11 |
| [Apache Kafka] 카프카 스트림즈, 카프카 커넥트, 카프카 미러메이커2 (2) | 2024.12.10 |
| [Apache Kafka] 카프카 기본 개념 (3) | 2024.12.10 |
| [Apache Kafka] 카프카 설치와 커맨드 라인 툴 (3) | 2024.12.04 |